DL4Jを使ったHadoopとSparkでの反復減少
反復減少(Iterative Reduce)を理解するには、比較的シンプルな先行処理であるMapReduceから始めると分かりやすいでしょう。
MapReduce
MapReduceは非常に大規模なデータセットを数多くのコアで同時に処理するための手法です。Google社のJeff Deanがこのメソッドを2004年発表の研究論文で紹介し、一年後にDoug Cuttingがこれに似た構造をYahooで実装しました。そしてこのCuttingの企画は後にApache Hadoopになりました。これらの企画はどちらもウェブのインデックス作成を一括処理することを目的としていました。
「MapReduce」という言葉は関数プログラミングから派生した2つのメソッドに由来するものです。Map とは同じ計算を値のリスト内の各要素に適用する演算で、新しい値のリストを生成します。Reduce とは値のリストに適用し、より少数の値へと組み合わせる演算です。
例えば、最もシンプルな形式だと、mapとreduceは、語彙の中の単語を数えるという作業で理解できます。語彙があるとすると、map は語彙の中のそれぞれの語の各インスタンスにキーと値のペアで値の1を与えます。reduce はこれらの各単語に関連付けられた値1を合計し、単語数を作成します。
MapReduceはこれより大きな規模で演算を行います。Map は、数々あるコアにデータを分散することにより、大規模なジョブをを小分けにし、これらの分割されたデータに同じ演算を実行するのです。Reduce は、これらの分散し、変換されたデータを1つのデータセットに統合します。すべての作業が一か所に集めれられ、追加の演算が適用されます。まるでとある星が膨張して赤色巨星になり、収縮して白色矮星になるように、Mapにより爆発し、Reduceにより萎みます。
反復MapReduce
多くのユースケースは、MapReduceを一回パスさせるのみで大丈夫ですが、機械学習やディープラーニングの場合は、反復的な性質を持つため、これでは不十分です。数々の段階を経てモデルはエラーが最小になるまで最適化アルゴリズムを使って「学習」するのです。
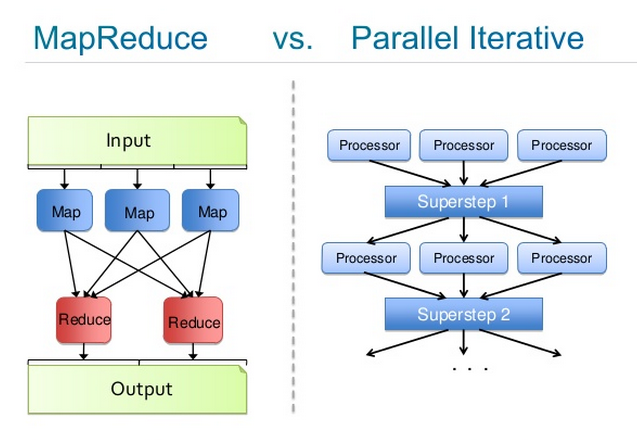
同じくJeff Deanから着想を得たもう一つの反復MapReduceも、一つでなく多数のパスをデータに実行できるYARNの枠組みと考えることができます。反復減少のアーキテクチャはMapReduceとは異なりますが、高レベルで見ると、MapReduce1の出力がMapReduce2の入力になっており、マッピングと減少の操作のシーケンスであるということが分かります。
入力を正確に分類するモデルを作成するために、非常に大規模なデータセットを使ってトレーニングしたいディープビリーフネットワークがあるとしましょう。ディープビリーフネットワークは、3つの関数で構成されています。入力を分類にマッピングするスコア関数、モデルの推測と正解の差を測定するエラー関数、推測でのエラーが最小になるまでモデルのパラメータを調節する最適化アルゴリズムです。
Mapはこれらの演算を分散システムの各コアに配置します。それから、この非常に大規模な入力データセットのバッチをこれらの数々あるコアに分散します。各コアにおいて、受け取った入力を使ってモデルをトレーニングします。Reduceは、新しい集計モデルを各コアに送り戻す前にこれらのモデルを使ってパラメーターの平均をとります。反復減少は学習高原(プラトー)とエラーの収縮がおさまるまで何回もこれを行います。
Josh Patterson作成の下記の画像は、この二つのプロセスを比較したものです。左の図はMapReduceのプロセスをクローズアップしたもので、右の図は反復のプロセスを表したものです。「Processor」とは、大規模なデータセットのバッチで学習するディープビリーフネットワークです。「Superstep」は、中央モデルが残りのクラスタに再分散される前のパラメータ平均化のインスタンスです。
HadoopとSpark
HadoopとSparkはどちらも一種のMapReduceや反復減少を行う分散型ランタイムです。Deeplearning4jはHadoop/YARNやSpark内でジョブとしての働きをします。例えば、YARNアプリとして呼び出し、実行、プロビジョニングが可能です。
Hadoopの場合、反復減少のワーカーは、変換されたパラメータをマスターに送り返す前に、分割データあるいはHDFSのブロックでデータを同期的に並列処理します。そしてマスターではパラメータが平均化され、各ワーカーのコアのモデルを更新するのに使用されます。MapReduceの場合、マップパスが消えますが、反復減少のワーカーは常駐します。このアーキテクチャは大まかにはSparkに似ています。
最新技術について少しお話しすると、GoogleもYahooもパラメターサーバーを操作し、ここで何十億ものパラメータを保管した後、処理を行うためにクラスタに分散しています。GoogleではGoogle Brainと呼ばれています。Andrew Ngが作成したもので、現在は彼の学生であるQuoc Leが引率しています。下図により、2015年度ごろのGoogleの生成スタックでMapReduceがどのような位置にあるかが分かります。
Deeplearning4jは、分散型ランタイムは互いに交換可能(同じという意味ではありません)だとみなしています。それらはどれもモジュラー型アーキテクチャ内にある1ディレクトリに過ぎず、入れ替え可能だからです。このため、企画全体が別々のスピードで進化することができ、一方でニューラルネットワークのアルゴリズムに専念し、他方でハードウェアに専念する他のモジュールとランタイムを分けることができます。また、Deeplearning4jのユーザーはAkka経由でAWS(Amazon Web Services)にノードをスピンし、スタンドアロンの分散型アーキテクチャを構築することもできます。
HadoopやSparkを含むすべてのスケールアウトのフォームは弊社のスケールアウト・リポジトリから利用可能です。
Deeplearning4jのコードのラインは、例えばSparkと混在させることができ、DL4Jの操作は他と同様に分散されます。