Iterative Reduce With DL4J on Hadoop and Spark
Understanding Iterative Reduce is easier if you start with its simpler predecessor, MapReduce.
MapReduce
MapReduce is a technique for processing very large datasets simultaneously over many cores. Jeff Dean of Google introduced the method in a 2004 research paper, and Doug Cutting implemented a similar structure a year later at Yahoo. Cutting’s project would eventually become Apache Hadoop. Both projects were created to batch index the Web, and have since found many other applications.
The word MapReduce refers to two methods derived from functional programming. Map is an operation that applies the same computation to every element in a list of values, producing a new list of values. Reduce is an operation that applies to a list of values and combines them into a smaller number of values.
For example, in their simplest form, map and reduce can understood with the example of a counting words in a vocab: given a vocabulary, map gives each instance of every word in the vocab a value of 1 in a key-value pair; reduce sums the 1s associated with each vocab word, creating the word count.
MapReduce operates on a larger scale. Map breaks down a very large job by distributing data to many cores, and running the same operation(s) on those data shards. Reduce consolidates all those scattered and transformed shards into one dataset, gathering all the work into one place and applying an additional operation. Map explodes and Reduce collapses, like a star expands to become a Red Giant, and shrinks to a White Dwarf.
Iterative MapReduce
While a single pass of MapReduce performs fine for many use cases, it is insufficient for machine- and deep learning, which are iterative in nature, since a model “learns” with an optimization algorithm that leads it to a point of minimal error over many steps.
You can think of Iterative MapReduce, also inspired by Jeff Dean, as a YARN framework that makes multiple passes on the data, rather than just one. While the architecture of Iterative Reduce is different from MapReduce, on a high level you can understand it as a sequence of map-reduce operations, where the output of MapReduce1 becomes the input of MapReduce2 and so forth.
Let’s say you have a deep-belief net that you want to train on a very large dataset to create a model that accurately classifies your inputs. A deep-belief net is composed of three functions: a scoring function that maps inputs to classifications; an error function that measures the difference between the model’s guesses and the correct answer; and optimization algorithm that adjusts the parameters of your model until they make the guesses with the least amount of error.
Map places all those operations on each core in your distributed system. Then it distributes batches of your very large input dataset over those many cores. On each core, a model is trained on the input it receives. Reduce takes all those models and averages the parameters, before sending the new, aggregate model back to each core. Iterative Reduce does that many times until learning plateaus and error ceases to shrink.
The image, created by Josh Patterson, below compares the two processes. On the left, you have a close-up of MapReduce; on the right, of Iterative. Each “Processor” is a deep-belief network at work, learning on batches of a larger dataset; each “Superstep” is an instance of parameter averaging, before the central model is redistributed to the rest of the cluster.
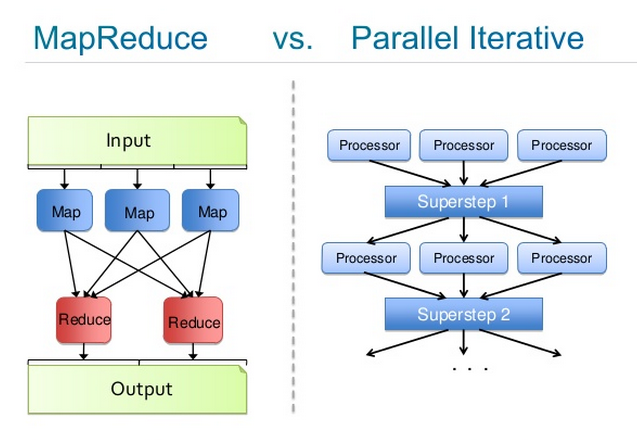
Hadoop & Spark
Both Hadoop and Spark are distributed run-times that perform a version of MapReduce and Iterative Reduce. Deeplearning4j works as a job within Hadoop/YARN or Spark. It can be called, run and provisioned as a YARN app, for example.
In Hadoop, Iterative Reduce workers sit on the their splits, or blocks of HDFS, and process data synchronously in parallel, before they send the their transformed parameters back to the master, where the parameters are averaged and used to update the model on each worker’s core. With MapReduce, the map path goes away, but Iterative Reduce workers stay resident. This architecture is roughly similar to Spark.
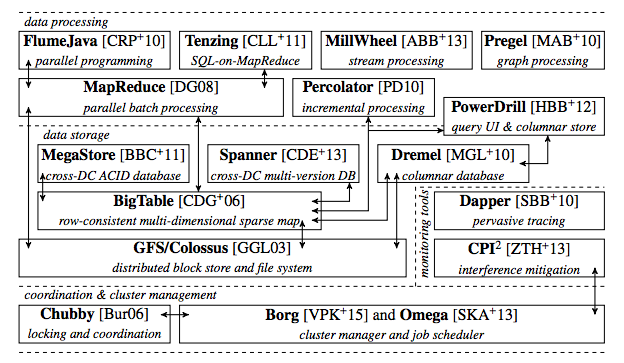
To provide a little context about the state-of-the-art, both Google and Yahoo operate parameter servers that store billions of parameters which are then distributed to the cluster for processing. Google’s is called the Google Brain, which was created by Andrew Ng and is now led by his student Quoc Le. Here’s a rough picture of the Google production stack circa 2015 to show you how MapReduce fits in.
Deeplearning4j considers distributed run-times to be interchangeable (but not necessarily equal); they are all simply a directory in a larger modular architecture that can be swapped in or out. This allows the overall project to evolve at different speeds, and separate run-times from other modules devoted to neural net algorithms on the one hand, and hardware on the other. Deeplearning4j users are also able to build a standalone distributed architecture via Akka, spinning out nodes on AWS.
Every form of scaleout including Hadoop and Spark is included in our scaleout repository.
Lines of Deeplearning4j code can be intermixed with Spark, for example, and DL4J operations will be distributed like any other.