Deeplearning4j on Spark
Deep learning is computationally intensive, so on very large datasets, speed matters. You can tackle the problem with faster hardware (usually GPUs), optimized code and some form of parallelism.
Data parallelism shards large datasets and hands those pieces to separate neural networks, say, each on its own core. Deeplearning4j relies on Spark for this, training models in parallel and iteratively averages the parameters they produce in a central model. (Model parallelism, discussed here by Jeff Dean et al, allows models to specialize on separate patches of a large dataset without averaging.)
Note that if you want a parameter server based approach (requires more setup!), please look at our new distributed page
Contents
- Overview
- Pre requisites
- How Distributed Network Training Occurs with DL4J on Spark
- A Minimal Example
- Configuring the TrainingMaster
- Dependencies for Training on Spark
- Spark Examples Repository
- Training with GPUs on Spark
- Configuring Memory for Spark on YARN
- Spark Locality Configuration for Improved Training Performance
- Performance Debugging and Collecting Training Performance Information
- Caching/Persisting RDD<DataSets> and RDD<INDArrays>
- Using Kryo Serialization with Deeplearning4j
- Using Intel MKL on Amazon Elastic MapReduce with Deeplearning4j
Pre requisites
This page assumes a working knowledge of Spark. If you are not familiar with setting up Spark clusters and running Spark jobs, this page will not teach you. Please consider studying Spark basics first, and then returning to this page. The Spark quick start is a great place to start with running Spark jobs.
If you want to run multiple models on the same server, consider using parallelwrapper instead.
GET STARTED WITH DEEP LEARNING
Parallelwrapper implements the same concepts (parameter averaging and gradient sharing) optimized for a single server.
You should use parallelwrapper when you have a big box (64 cores or more) or multiple GPUs.
Note that you can use multiple GPUs and cuDNN with Spark. The most difficult part of this will be cluster setup. It is not DL4J’s responsibility, beyond being a Spark job.
If you have not run JVM-based Spark jobs before, we recommend building an uber JAR using the Maven Shade plugin .
If you would like a managed Spark cluster set up for you, please contact us. Various cloud services such as Elastic map reduce are another way of running and managing a Spark cluster.
The rest of this page covers the details for running a Spark job including how to customize the Spark job and how to use the Spark interface for DL4J.
Overview
Deeplearning4j supports training neural networks on a Spark cluster, in order to accelerate network training.
Similar to DL4J’s MultiLayerNetwork and ComputationGraph classes, DL4J defines two classes for training neural networks on Spark:
- SparkDl4jMultiLayer, a wrapper around MultiLayerNetwork
- SparkComputationGraph, a wrapper around ComputationGraph
Because these two classes are wrappers around the stardard single-machine classes, the network configuration process (i.e., creating a MultiLayerConfiguration or ComputationGraphConfiguration) is identical in both standard and distributed training. Distributed on Spark differs from local training in two respects, however: how data is loaded, and how training is set up (requiring some additional cluster-specific configuration).
The typical workflow for training a network on a Spark cluster (using spark-submit) is as follows.
- Create your network training class. Typically, this will involve code for:
- Specifying your network configuration (MultiLayerConfiguration or ComputationGraphConfiguration), as you would for single-machine training
- Creating a TrainingMaster instance: this specifies how distributed training will be conducted in practice (more on this later)
- Creating the SparkDl4jMultiLayer or SparkComputationGraph instance using the network configuration and TrainingMaster objects
- Load your training data. There are a number of different methods of loading data, with different tradeoffs; further details will be provided in future documentation
- Calling the appropriate
fitmethod on the SparkDl4jMultiLayer or SparkComputationGraph instance - Saving or using the trained network (the trained MultiLayerNetwork or ComputationGraph instance)
- Package your jar file ready for Spark submit
- If you are using maven, running “mvn package -DskipTests” is one approach
- Call Spark submit with the appropriate launch configuration for your cluster
Note: For single machine training, Spark local can be used with DL4J, though this is not recommended (due to the synchronization and serialization overheads of Spark). Instead, consider the following:
- For single CPU/GPU systems, use standard MultiLayerNetwork or ComputationGraph training
- For multi-CPU/GPU systems, use ParallelWrapper. This is functionally equivalent to running Spark in local mode, though has lower overhead (and hence provides better training performance).
How Distributed Network Training Occurs with DL4J on Spark
The current version of DL4J uses a process of parameter averaging in order to train a network. Future versions may additionally include other distributed network training approaches.
The process of training a network using parameter averaging is conceptually quite simple:
- The master (Spark driver) starts with an initial network configuration and parameters
- Data is split into a number of subsets, based on the configuration of the TrainingMaster
- Iterate over the data splits. For each split of the training data:
- Distribute the configuration, parameters (and if applicable, network updater state for momentum/rmsprop/adagrad) from the master to each worker
- Fit each worker on its portion of the split
- Average the parameters (and if applicable, updater state) and return the averaged results to the master
- Training is complete, with the master having a copy of the trained network
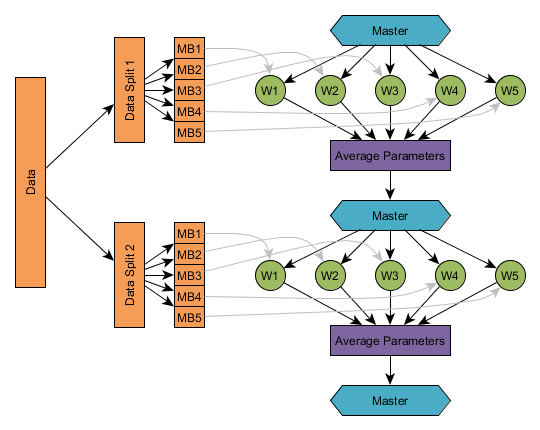
For example, the diagram below shows the parameter averaging process with 5 workers (W1, …, W5) and a parameter averaging frequency of 1. Just as with offline training, a training data set is split up into a number of subsets (generally known as minibatches, in the non-distributed setting); training proceeds over each split, with each worker getting a subset of the split. In practice, the number of splits is determined automatically, based on the training configuration (based on number of workers, averaging frequency and worker minibatch sizes - see configuration section).
A Minimal Example
This section shows the minimal set of components that you need in order to train a network on Spark. Details on the various approaches to loading data are forthcoming.
JavaSparkContext sc = ...;
JavaRDD<DataSet> trainingData = ...;
MultiLayerConfiguration networkConfig = ...;
//Create the TrainingMaster instance
int examplesPerDataSetObject = 1;
TrainingMaster trainingMaster = new ParameterAveragingTrainingMaster.Builder(examplesPerDataSetObject)
.(other configuration options)
.build();
//Create the SparkDl4jMultiLayer instance
SparkDl4jMultiLayer sparkNetwork = new SparkDl4jMultiLayer(sc, networkConfig, trainingMaster);
//Fit the network using the training data:
sparkNetwork.fit(trainingData);
Using the output from SparkDl4jMultiLayer/ComputationGraph
Due to the spark networks being a wrapper around the multi layer network and computation graph apis, you have to obtain the underlying final network from the spark network after it is done training. The reason for this is due to the fact the data parallel training is actually averaging several networks at once during the training. This means that there is no “one” network until you get to the final output which is an averaged set of parameters accumulated across several workers.
Knowing this, we should obtain the underlying reference on both SparkComputationGraph and SparkDl4jMultiLayer respectively using the methods getNetwork and getNetwork respectively for each kind of wrapper.
You’ll note that the fit output returns the same underlying network as well directly. In that case youc an just use:
JavaSparkContext sc = ...;
JavaRDD<DataSet> trainingData = ...;
MultiLayerConfiguration networkConfig = ...;
//Create the TrainingMaster instance
int examplesPerDataSetObject = 1;
TrainingMaster trainingMaster = new ParameterAveragingTrainingMaster.Builder(examplesPerDataSetObject)
.(other configuration options)
.build();
//Create the SparkDl4jMultiLayer instance
SparkDl4jMultiLayer sparkNetwork = new SparkDl4jMultiLayer(sc, networkConfig, trainingMaster);
//Fit the network using the training data:
MultiLayerNetwork outputNetwork = sparkNetwork.fit(trainingData);
Configuring the TrainingMaster
A TrainingMaster in DL4J is an abstraction (interface) that allows for multiple different training implementations to be used with SparkDl4jMultiLayer and SparkComputationGraph.
Currently DL4J has one implementation, the ParameterAveragingTrainingMaster. This implements the parameter averaging process shown in the image above. To create one, use the builder pattern:
TrainingMaster tm = new ParameterAveragingTrainingMaster.Builder(int dataSetObjectSize)
... (your configuration here)
.build();
The ParameterAveragingTrainingMaster defines a number of configuration options that control how training is executed:
- dataSetObjectSize: Required option. This is specified in the builder constructor. This value specifies how many examples are in each DataSet object. As a general rule,
- If you are training with pre-processed DataSet objects, this will be the size of those preprocessed DataSets
- If you are training directly from Strings (for example, CSV data to a
RDD<DataSet>though a number of steps) then this will usually be 1
- batchSizePerWorker: This controls the minibatch size for each worker. This is analagous to the minibatch size used when training on a single machine. Put another way: it is the number of examples used for each parameter update in each worker.
- averagingFrequency: This controls how frequently the parameters are averaged and redistributed, in terms of number of minibatches of size batchSizePerWorker. As a general rule:
- Low averaging periods (for example, averagingFrequency=1) may be inefficient (too much network communication and initialization overhead, relative to computation)
- Large averaging periods (for example, averagingFrequency=200) may result in poor performance (parameters in each worker instance may diverge significantly)
- Averaging periods in the range of 5-10 minibatches is usually a safe default choice.
- workerPrefetchNumBatches: Spark workers are capable of asynchorously prefetching a number of minibatches (DataSet objects), to avoid waiting for the data to be loaded.
- Setting this value to 0 disables prefetching.
- A value of 2 is often a sensible default. Much larger values are unlikely to help in many circumstances (but will use more memory)
- saveUpdater: In DL4J, training methods such as momentum, RMSProp and AdaGrad are known as ‘updaters’. Most of these updaters have internal history or state.
- If saveUpdater is set to true: the updater state (at each worker) will be averaged and returned to the master along with the parameters; the current updater state will also be distributed from the master to the workers. This adds extra time and network traffic, but may improve training results.
- If saveUpdater is set to false: the updater state (at each worker) is discarded, and the updater is reset/reinitialized in each worker.
- rddTrainingApproach: As of version 0.6.0 and later, DL4J provides two approaches when training from a
RDD<DataSet>orRDD<MultiDataSet>. These areRDDTrainingApproach.ExportandRDDTrainingApproach.Direct- Export: (Default) This first saves the
RDD<DataSet>to disk, in batched and serialized form. The executors then load the DataSet objects asynchronously, as required. This approach performs better than the Direct approach, especially for large data sets and multiple epochs. It avoids the split and repartitioning overhead of the Direct method, and also uses less memory. Temporary files can be deleted usingTrainingMaster.deleteTempFiles() - Direct: This is how DL4J operated in earlier releases. It may provide good performance for small data sets that fit entirely into memory.
- Export: (Default) This first saves the
- exportDirectory: only used with the Export training approach (above). This controls where the temporary data files are stored. Default: use
{hadoop.tmp.dir}/dl4j/directory, where{hadoop.tmp.dir}is the Hadoop temporary directory property value. - storageLevel: Only applies when (a) using Direct training approach, and (b) training from a
RDD<DataSet>orRDD<MultiDataSet>. This is the storage level that DL4J will persist the RDDs at. Default: StorageLevel.MEMORY_ONLY_SER. - storageLevelStreams: Only applies when using the
fitPaths(RDD<String>)method. This is the storage level that DL4J will use for persisting theRDD<String>. Default: StorageLevel.MEMORY_ONLY. The default value should be ok in almost all circumstances. - repartition: Configuration setting for when data should be repartitioned. The ParameterAveragingTrainingMaster does a mapParititons operation; consequently, the number of partitions (and, the values in each partition) matters a lot for proper cluster utilization. However, repartitioning is not a free operation, as some data necessarily has to be copied across the network. The following options are available:
- Always: Default option. That is, repartition data to ensure the correct number of partitions. Recommended, especially with RDDTrainingApproach.Export (default as of 0.6.0) or
fitPaths(RDD<String>) - Never: Never repartition the data, no matter how imbalanced the partitions may be.
- NumPartitionsWorkersDiffers: Repartition only if the number of partitions and the number of workers (total number of cores) differs. Note however that even if the number of partitions is equal to the total number of cores, this does not guarantee that the correct number of DataSet objects is present in each partition: some partitions may be much larger or smaller than others.
- Always: Default option. That is, repartition data to ensure the correct number of partitions. Recommended, especially with RDDTrainingApproach.Export (default as of 0.6.0) or
- repartitionStrategy: Strategy by which repartitioning should be done
- Balanced: (Default) This is a custom repartitioning strategy defined by DL4J. It attempts to ensure that each partition is more balanced (in terms of number of objects) compared to the SparkDefault option. However, in practice this requires an additional count operation to execute; in some cases (most notably in small networks, or those with a small amount of computation per minibatch), the benefit may not outweigh additional overhead of executing the better repartitioning. Recommended, especially with RDDTrainingApproach.Export (default as of 0.5.1) or
fitPaths(RDD<String>) - SparkDefault: This is the stardard repartitioning strategy used by Spark. Essentially, each object in the initial RDD is mapped to one of N RDDs independently at random. Consequently, the partitions may not be optimally balanced; this can be especially problematic with smaller RDDs, such as those used for preprocessed DataSet objects and frequent averaging periods (simply due to random sampling variation).
- Balanced: (Default) This is a custom repartitioning strategy defined by DL4J. It attempts to ensure that each partition is more balanced (in terms of number of objects) compared to the SparkDefault option. However, in practice this requires an additional count operation to execute; in some cases (most notably in small networks, or those with a small amount of computation per minibatch), the benefit may not outweigh additional overhead of executing the better repartitioning. Recommended, especially with RDDTrainingApproach.Export (default as of 0.5.1) or
Dependencies for Training on Spark
To use DL4J on Spark, you’ll need to include the deeplearning4j-spark dependency:
<dependency>
<groupId>org.deeplearning4j</groupId>
<artifactId>dl4j-spark_${scala.binary.version}</artifactId>
<version>${dl4j.version}</version>
</dependency>
Note that ${scala.binary.version} is a Maven property with the value 2.10 or 2.11 and should match the version of Spark you are using.
Spark Examples Repository
The Deeplearning4j examples repo (old examples here) contains a number of Spark examples.
Training with GPUs on Spark
There are some issues to be aware of when running Deeplearning4j with CUDA on Spark, with cluster managers such as YARN.
YARN and GPUs
YARN is a commonly used cluster resource management/scheduling tool for Hadoop clusters. Running Deeplearning4j with GPUs on Spark+YARN is possible, but (unlike memory and CPU resources) YARN does not track/handle GPUs as a resource. Consequently, some additional steps are typically required to run DL4J with GPUs on YARN. This is problematic for two reasons:
- On heterogeneous-hardware clusters (i.e., some machines with GPUs, others without), as YARN won’t natively allocate your jobs only to machines that have GPUs
- YARN may try to schedule two or more GPU-utilizing jobs to a single machine/GPU
A workaround to this is to utilize node labels (which are available with YARN versions 2.6 or greater). Node labels provide a way to tag or group machines based on your own criteria - in this case, the presence or absence of GPUs. After enabling node labels in the YARN configuration, node labels can be created, and then can be assigned to machines in the cluster. Spark jobs can then be limited to using GPU-containing machines only, by specifying a node label.
Some resources on node labels - and how to configure them - can be found at the following links:
- https://hadoop.apache.org/docs/r2.7.3/hadoop-yarn/hadoop-yarn-site/NodeLabel.html
- https://docs.hortonworks.com/HDPDocuments/HDP2/HDP-2.4.2/bk_yarn_resource_mgt/content/configuring_node_labels.html.
- https://developer.ibm.com/hadoop/2017/03/10/yarn-node-labels/
To launch GPU jobs on YARN:
- Ensure node labels are enabled in the YARN configuration
- Create a label (or, multiple labels) for the GPU machines
- Assign each GPU machine you want to use for training to the previously-created node label
- Add
--conf spark.yarn.executor.nodeLabelExpression=YOUR_NODE_LABELto your Spark submit launch configuration
Note that multiple labels can be assigned to each node. Multiple labels can be utilized to obtain more fine-grained (albeit manual) control over job/node scheduling, and is a possible workaround to avoid YARN over-allocating GPU resources.
There are some issues to be aware of when using DL4J on Spark/YARN and GPUs.
- As with single-machine training in DL4J, CUDA must be installed and NVCC must be available on the path for executing tasks
- Since YARN does not partition or contain GPU usage, you should make sure it can only schedule a single GPU task on any single-GPU node. This can be done by requiring enough CPU and memory in your GPU-using job that the executor has no capacity left over for another such job. Otherwise, YARN might schedule multiple GPU jobs on the same executor, even if it does not have enough GPU ressources to satisfy the demands of both jobs.
Three workarounds are available to avoid failures due to scheduling:
First, use multiple labels to manually control scheduling, as discussed above.
Second, allocate sufficient resources (cores, memory) to the containers to ensure no other GPU-utilizing tasks are scheduled on each node.
Third, it is possible to utilize containers (specifically, the Docker container executor), where the GPU is declared as being used in the container, via the devices cgroup - this ensures that GPU is not allocated to multiple tasks. A simpler approach is to use nvidia-docker containers, which handles this declaration for you.
Requirements for the Docker container executor:
- Hadoop version 2.6.0 or later
- An operating system that supports Docker (cgroups and namespaces are required, hence a Linux kernel version 3.x or later is required. Some operating systems, such as CentOS 6 and RHEL 6 and earlier are not supported).
- Docker client installed and configured on each node
- A properly configured docker image to launch your jobs
Further details on the Docker container executor can be found here.
Mesos and GPUs
Apache Mesos is an another cluster resource management tool. Unlike YARN, Mesos has built-in support for Nvidia GPUs (since version 1.0.0), and does not have the GPU over-allocation issues of YARN. Consequently, (all other things being equal) running DL4J+GPUs on Mesos is easier than running the same task on YARN.
Configuring Memory for Spark on YARN
Apache Hadoop YARN is a commonly used resource manager for Hadoop clusters (Apache Mesos being an alternative). When submitting a job to a cluster via Spark submit, it is necessary to specify a small number of configuration options, such as the number of executors, the number of cores per executor and amount of memory for each executor.
To get the best performance out of DL4J when training on Spark (and to avoid exceeding memory limits), some additional memory configuration is required. This section explains why this is necessary, and how to do it in practice.
How Deeplearning4j (and ND4J) Manages Memory
Deeplearning4j is built upon the numerical computing library ND4J. The neural network implementations in DL4J are built using the matrix and vector operations in ND4J.
One key design aspect of ND4J is the fact that it utilizes off-heap memory management. This means that the memory allocated for INDArrays by ND4J is not allocated on on the JVM heap (as a standard Java object would be); instead, it is allocated in a separate pool of memory, outside of the JVM. This memory management is implemented using JavaCPP.
Off-heap memory management provides a number of benefits. Most notably, it allows for efficient use of high-performance native (c++) code for numerical operations (using BLAS libraries such as OpenBLAS and Intel MKL, as well as the C++ library Libnd4j). Off-heap memory management is also necessary for efficient GPU operations with CUDA. If memory was allocated on the JVM heap (as it is in some other JVM BLAS implementations), it would be necessary to first copy the data from the JVM, perform the operations, and then copy the result back - adding both a memory and time overhead to each operation. Instead, ND4J can simply pass pointers around for numerical operations - entirely avoiding the data copying issue.
The important point here is that the on-heap (JVM) memory and off-heap (ND4J/JavaCPP) are two separate memory pools. It is possible to configure the size of each independently; by default, JavaCPP will allow the off-heap memory allocation to grow as large as the Runtime.maxMemory() setting (see: code) - this default is essentially equivalent to the size of the JVM ‘Xmx’ memory setting, used for configuring Java memory.
To manually control the maximum amount of off-heap memory that JavaCPP can allocate, we can set the org.bytedeco.javacpp.maxbytes system property. For a single JVM run locally, we would pass -Dorg.bytedeco.javacpp.maxbytes=1073741824 to limit the off-heap memory allocation to 1GB. We will see how to configure this for Spark on YARN in a later section.
How YARN Manages Memory
As noted, YARN is a cluster resource manager. When submitting a compute task (such as DL4J Spark network training) to a YARN-managed cluster, it is YARN that is responsible for managing the allocation of a limited pool of resources (memory, CPU cores) to your job (and all other jobs). For more details on YARN and resource allocation, see this and this.
The key points for our purposes are as follows:
- YARN jobs run in containers, with a fixed amount of memory for each
- The amount of memory allocated to a YARN container is the sum of the on-heap (i.e., JVM memory size) and off-heap (“memory overhead” in YARN terms) memory requested by the user
- If a task exceeds the amount of memory available allocated to the container, YARN may kill the container, and hence the executor running in it. The exact behaviour will depend on the YARN configuration.
- Programs that exceed the container memory limits usually do so due to off-heap memory; the maximum amount of on-heap (JVM) memory is fixed as a launch parameter via Spark submit.
There are two key configuration options for controlling how much memory YARN will allocate to a container.
spark.executor.memory: This is the standard JVM memory allocation. It is analogous to the Xmx setting for a single JVM.spark.yarn.executor.memoryOverhead: This is the amount of ‘extra’ memory allocated to the container. It is not allocated to the JVM, and hence is available for code that utilizes off-heap memory (including ND4J/JavaCPP).
By default, the spark.yarn.executor.memoryOverhead setting is equal to 10% of the executor memory, with a minimum of 384 MB.
For more details, see the Apache Spark documentation for YARN.
Because of the extensive use of off-heap memory by ND4J, it is generally necessary to increase the memory overhead setting when training on Spark.
Configuring Memory for Deeplearning4j Spark Training on YARN
To recap the previous sections, when running distributed neural network training on Spark via YARN, it is necessary to do the following:
- Specify the executor JVM memory amount, using
spark.executor.memory - Specify the YARN container memory overhead, using
spark.yarn.executor.memoryOverhead - Let ND4J/JavaCPP know how much off-heap memory it is allowed to use, using the
org.bytedeco.javacpp.maxbytessystem property
When setting these values, there are some things to keep in mind.
First, the sum of spark.executor.memory and spark.yarn.executor.memoryOverhead must be less than the maximum amount of memory that YARN will allocate to a single container. You can generally find this limit in the YARN configuration or YARN resource manager web UI. If you exceed this limit, YARN is likely to reject your job.
Second, the value for org.bytedeco.javacpp.maxbytes should be strictly less than spark.yarn.executor.memoryOverhead. Recall by default the memoryOverhead setting is 10% of the executor memory - this is because the JVM itself (and possibly other libraries) may require some off-heap memory. Consequently, we don’t want JavaCPP to use up the entire non-JVM allocation of memory.
Third, because DL4J/ND4J makes use off-heap memory for data, parameters and activations, we can afford to allocate less to the JVM (i.e., executor.memory) than we might otherwise do. Of course, we still require enough JVM memory for Spark itself (and any other libraries we are using), so we don’t want to reduce this too much.
Here’s an example. Suppose we are running Spark training, and want to configure our memory as follows:
- 4 executors, 8 cores each
- Maximum container memory allocatable by YARN: 11GB
- JVM (executors and driver) memory: 4GB
- ND4J/JavaCPP off-heap memory (executors and driver): 5GB
- Extra off-heap memory: 1GB
The total off-heap memory is 5+1=6GB; the total memory (JVM + off-heap/overhead) is 4+6=10GB, which is less than the YARN maximum allocation of 11GB. Note that the JavaCPP memory is specified in bytes, and 5GB is 5,368,709,120 bytes; YARN memory overhead is specified in MB, and 6GB is 6,144MB.
The arguments for Spark submit would be specified as follows:
--class my.class.name.here --num-executors 4 --executor-cores 8 --executor-memory 4G --driver-memory 4G --conf "spark.executor.extraJavaOptions=-Dorg.bytedeco.javacpp.maxbytes=5368709120" --conf "spark.driver.extraJavaOptions=-Dorg.bytedeco.javacpp.maxbytes=5368709120" --conf spark.yarn.executor.memoryOverhead=6144
Spark Locality Configuration for Improved Training Performance
Configuring Spark locality settings is an optional configuration option that can improve training performance.
The summary: adding --conf spark.locality.wait=0 to your Spark submit configuration may reduce training times, by scheduling the network fit operations to be started sooner.
Why Configuring Spark Locality Configuration Can Improve Performance
Spark has a number of configuration options for how it controls execution. One important component of this is the settings around locality. Locality, simply put, refers to where data is relative to where data can be processed. Suppose an executor is free, but data would have to be copied across the network, in order to process it. Spark must decide whether it should execute that network transfer, or if instead it should wait for an executor that has local access to the data to become free. By default, instead of transferring data immediately, Spark will wait a bit before transferring data across the network to a free executor. This default behaviour might work well for other tasks, but isn’t an ideal fit for maximizing cluster utilization when training networks with Deeplearning4j.
Deep learning is computationally intensive, and hence the amount of computation per input DataSet object is relatively high. Furthermore, during Spark training, DL4J ensures there is exactly one task (partition) per executor. Consequently, we are always better off immediately transferring data to a free executor, rather than waiting for another executor to become free. The computation time will outweigh any network transfer time.
The way we can instruct Spark to do this is to add --conf spark.locality.wait=0 to our Spark submit configuration.
For more details, see the Spark Tuning Guide - Data Locality and Spark Configuration Guide.
Performance Debugging and Collecting Training Performance Information
Deeplearning4j’s Spark training implementation has the ability to collect performance information (such as how long it takes to create the inital network, receive broadcast data, perform network fitting operations, etc). This information can be useful to isolate and debug any performance issues when training a network with Deeplearning4j on Spark.
To collect and export these performance statistics, use the following:
SparkDl4jMultiLayer sparkNet = new SparkDl4jMultiLayer(...);
sparkNet.setCollectTrainingStats(true); //Enable collection
sparkNet.fit(trainData); //Train network in the normal way
SparkTrainingStats stats = sparkNet.getSparkTrainingStats(); //Get the collect stats information
StatsUtils.exportStatsAsHtml(stats, "SparkStats.html", sc); //Export it to a stand-alone HTML file
Note that as of Deeplearning4j version 0.6.0, the current HTML rendering implementation doesn’t scale well to a large amount of stats: i.e., large clusters and long-running jobs. This is being worked on and will be improved in future releases.
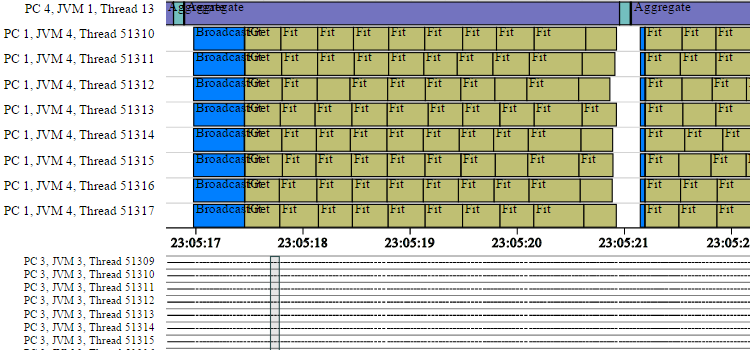
Timeline information available via Spark training stats collection functionality:
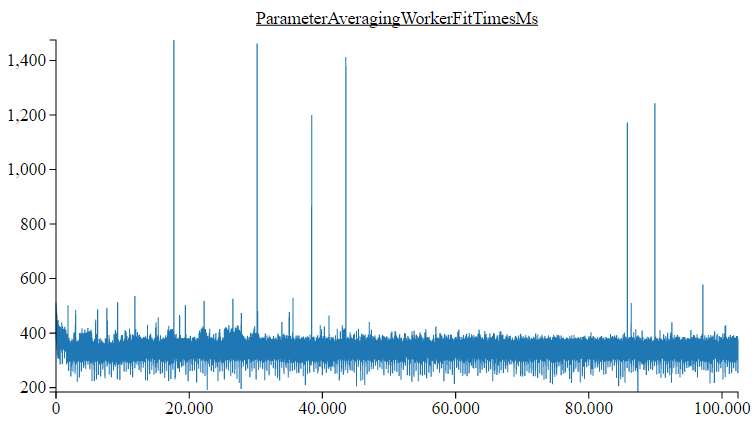
One of the charts (Worker fit(DataSet) times) available via Spark Stats
Debugging “Error querying NTP server” when collecting performance information
By default, the Spark training performance stats rely on a Network Time Protocal (NTP) implementation to ensure that the event timestamps correspond across machines. Without this, there is no guarantee that clocks on each worker machine are accurate - they could be incorrect by an arbitrary/unknown amount. Without a NTP implementation, accurately plotting of timeline information (shown in the timeline figure above) is impossible.
It is possible to get errors like NTPTimeSource: Error querying NTP server, attempt 1 of 10. Sometimes these failures are transient (later retries will work) and can be ignored.
However, if the Spark cluster is configured such that one or more of the workers cannot access the internet (or specifically, the NTP server), all retries can fail.
Two solutions are available:
- Don’t use
sparkNet.setCollectTrainingStats(true)- this functionality is optional (not required for training), and is disabled by default - Set the system to use the local machine clock instead of the NTP server, as the time source (note however that the timeline information may be very inaccurate as a result)
To use the system clock time source, add the following to Spark submit:
--conf spark.driver.extraJavaOptions=-Dorg.deeplearning4j.spark.time.TimeSource=org.deeplearning4j.spark.time.SystemClockTimeSource
--conf spark.executor.extraJavaOptions=-Dorg.deeplearning4j.spark.time.TimeSource=org.deeplearning4j.spark.time.SystemClockTimeSource
Caching/Persisting RDD<DataSets> and RDD<INDArrays>
Spark has some quirks regarding how it handles Java objects with large off-heap components, such as the DataSet and INDArray objects used in Deeplearning4j. This section explains the issues related to caching/persisting these objects.
The key points to know about are:
MEMORY_ONLYandMEMORY_AND_DISKpersistence can be problematic with off-heap memory, due to Spark not properly estimating the size of objects in the RDD. This can lead to out of memory issues.- When persisting a
RDD<DataSet>orRDD<INDArray>for re-use, useMEMORY_ONLY_SERorMEMORY_AND_DISK_SER - As of Deeplearning4j 0.5.1 and later, by default the training data (
RDD<DataSet>) will be exported to disk first (this improves performance, especially for large training sets); it is neither necessary nor recommended to manually persist/cache your training data RDDs. (This behaviour is configurable using the rddTrainingApproach configuration option).
Why MEMORY_ONLY_SER or MEMORY_AND_DISK_SER Are Recommended
One of the way that Apache Spark improves performance is by allowing users to cache data in memory. This can be done using the RDD.cache() or RDD.persist(StorageLevel.MEMORY_ONLY()) to store the contents in-memory, in deserialized (i.e., standard Java object) form.
The basic idea is simple: if you persist a RDD, you can re-use it from memory (or disk, depending on configuration) without having to recalculate it. However, large RDDs may not entirely fit into memory. In this case, some parts of the RDD have to be recomputed or loaded from disk, depending on the storage level used. Furthermore, to avoid using too much memory, Spark will drop parts (blocks) of an RDD when required.
The main storage levels available in Spark are listed below. For an explanation of these, see the Spark Programming Guide.
- MEMORY_ONLY
- MEMORY_AND_DISK
- MEMORY_ONLY_SER
- MEMORY_AND_DISK_SER
- DISK_ONLY
The problem with Spark is how it handles memory. In particular, Spark will drop part of an RDD (a block) based on the estimated size of that block. The way Spark estimates the size of a block depends on the persistence level. For MEMORY_ONLY and MEMORY_AND_DISK persistence, this is done by walking the Java object graph - i.e., look at the fields in an object and recursively estimate the size of those objects. This process does not however take into account the off-heap memory used by Deeplearning4j or ND4J. For objects like DataSets and INDArrays (which are stored almost entirely off-heap), Spark significantly under-estimates the true size of the objects using this process. Furthermore, Spark considers only the amount of on-heap memory use when deciding whether to keep or drop blocks. Because DataSet and INDArray objects have a very small on-heap size, Spark will keep too many of them around with MEMORY_ONLY and MEMORY_AND_DISK persistence, resulting in off-heap memory being exhausted, causing out of memory issues.
However, for MEMORY_ONLY_SER and MEMORY_AND_DISK_SER Spark stores blocks in serialized form, on the Java heap. The size of objects stored in serialized form can be estimated accurately by Spark (there is no off-heap memory component for the serialized objects) and consequently Spark will drop blocks when required - avoiding any out of memory issues.
Using Kryo Serialization with Deeplearning4j
Kryo is a serialization library commonly used with Apache Spark. It proposes to increase performance by reducing the amount of time taken to serialize objects. However, Kryo has difficulties working with the off-heap data structures in ND4J. To use Kryo serialization with ND4J on Apache Spark, it is necessary to set up some extra configuration for Spark. If Kryo is not correctly configured, it is possible to get NullPointerExceptions on some of the INDArray fields, due to incorrect serialization.
To use Kryo, add the appropriate nd4j-kryo dependency and configure the Spark configuration to use the Nd4j Kryo Registrator, as follows:
SparkConf conf = new SparkConf();
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer");
conf.set("spark.kryo.registrator", "org.nd4j.Nd4jRegistrator");
Note that when using Deeplearning4j’s SparkDl4jMultiLayer or SparkComputationGraph classes, a warning will be logged if the Kryo configuration is incorrect.
Using Intel MKL on Amazon Elastic MapReduce with Deeplearning4j
Releases of DL4J available on Maven Cental are distributed with OpenBLAS. Thus this section does not apply to users who are using using versions of Deeplearning4j on Maven Central.
If DL4J is built from source with Intel MKL as the BLAS library, some additional configuration is required to make this work on Amazon Elastic MapReduce. When creating a cluster in EMR, to use Intel MKL it is necessary to provide some additional configuration.
Under the Create Cluster -> Advanced Options -> Edit Software Settings, add the following:
[
{
"Classification": "hadoop-env",
"Configurations": [
{
"Classification": "export",
"Configurations": [],
"Properties": {
"MKL_THREADING_LAYER": "GNU",
"LD_PRELOAD": "/usr/lib64/libgomp.so.1"
}
}
],
"Properties": {}
}
]
Resources
- Deeplearning4j Examples Repo
- ND4S: N-Dimensional Arrays for Scala
- ND4J, Scala & Scientific Computing
- Intro to Iterative Reduce
Notes
Warning!!! Spark on Ubuntu 16.04 bug may affect DL4J users
When running a Spark on YARN cluster on Ubuntu 16.04 machines, chances are that after finishing a job, all processes owned by the user running Hadoop/YARN are killed. This is related to a bug in Ubuntu, which is documented at https://bugs.launchpad.net/ubuntu/+source/procps/+bug/1610499. There’s also a Stackoverflow discussion about it at http://stackoverflow.com/questions/38419078/logouts-while-running-hadoop-under-ubuntu-16-04.
Some workarounds are suggested.
Option:1
Add
[login]
KillUserProcesses=no
to /etc/systemd/logind.conf, and reboot.
Option:2
Copy the /bin/kill binary from Ubuntu 14.04 and use that one instead.
Option:3
Downgrade to Ubuntu 14.04
Option:4
run sudo loginctl enable-linger hadoop_user_name on cluster nodes