컨볼루션 네트워크
차례
컨볼루션 네트워크 소개
컨볼루션 네트워크(컨브넷)는 그림이나 사진(이미지)에서 사물을 인식하는데 쓰이는 기술입니다. 예를 들어 사람의 얼굴이나 표지판, 동물, 식물, 자동차 등 온갖 종류의 사물이 그 대상이 될 수 있습니다. 또 문자나 단어를 인식하는데에도 쓰일 수 있으며, 더 나아가 음성 인식에서도 쓰이곤 합니다.
컨브넷은 심층 신경망의 유행을 선도하고 있습니다. 최근에 있었던 컴퓨터 비전의 기술 발전은 거의 다 컨브넷과 관계가 있으며 자동 운전 기술, 각종 로봇 기술, 드론, 시각 장애인용 기술 등 산업계에도 크게 영향을 끼치고 있습니다.
이미지가 4차원 텐서인 이유
컨브넷은 이미지 데이터를 텐서 타입의 데이터로 받아들입니다. 참고로 텐서는 2차원 데이터인 행렬에 차원을 추가한 N-차원 어레이입니다.
4차원 텐서는 시각화하기가 까다롭습니다. 우선 간단한 비유를 통해 텐서를 설명 드리겠습니다. 일단, 스칼라 값은 숫자 하나에 해당하고(예: 7) 벡터는 숫자 여러 개의 어레이에 해당합니다(예: [7,8,9]). 그리고 행렬은 액셀 시트처럼 여러 행과 열을 숫자로 채운 것입니다. 차원으로 설명하면 스칼라는 0차원 점이고, 벡터는 1차원 선에 해당합니다. 행렬은 2차원 평면이 되고, 2차원 평면을 쌓으면 3차원의 직육면체가 됩니다. 그러면 이 직육면체를 이루고 있는 행렬의 성분(0차원 스칼라 값)을 벡터 형태의 피쳐 맵(Feature Map)으로 대체하면, 이 직육면체는 4차원 텐서가 됩니다. 예를 들어 볼까요? 우선 2x2 정방 행렬을 하나 만들어봅시다.
[ 1, 2 ]
[ 5, 8 ]
텐서는 이 행렬의 각 성분을 더 큰 차원으로 바꿔주면 쉽게 만들 수 있습니다. 직육면체 형태의 3차원 텐서를 상상해보십시오. 액셀 시트를 두 장 포개놓은 것을 상상하시면 됩니다. 아래 그림은 2x3x2 크기의 텐서를 평면에 그려본 것입니다.

이 텐서 데이터를 직접 코딩할 경우 [[[2,3],[3,5],[4,7]],[[3,4],[4,6],[5,8]]]가 됩니다. 아래 그림은 거대한 3차원 텐서를 입체적으로 그린 것 입니다.
즉, 텐서는 어레이의 어레이라고 생각할 수 있습니다. 그리고 그 어레이를 또 다른 어레이에 넣어서 차원을 얼마든지 확장할 수 있습니다. 4차원 텐서는 그 중에서 그나마 간단한 형태라고 할 수 있습니다. 위의 그림에서 각 (스칼라)값을 벡터로 바꿔주면 전체 차원이 하나 증가하면서 4차원 텐서가 됩니다. 그리고 컨볼루션 네트워크는 4차원 데이터를 다룹니다. 아래 그림이 컨볼루션 네트워크가 다루는 4차원 데이터의 예 입니다.
ND4J와 Deeplearning4j는 NDArray로 텐서를 표현합니다. 말 그대로 N차원 어레이를 담을 수 있는 데이터 타입으로, 이를 차수(order)를 이용해 표현하기도 합니다. 예를 들어 4차 어레이는 4차원의 어레이입니다.
이미지의 너비와 높이는 특별한 설명이 필요하지 않겠죠? 이미지는 너비와 높이만 있으면, 즉 2차원 행렬로 설명할 수 있지만 이미지 데이터는 3차원 행렬이 필요합니다. 이 세 번째 차원을 깊이(depth)라고 합니다. 깊이가 필요한 이유는 컴퓨터에서 이미지 데이터를 저장할 때 RGB(Red-Green-Blue)로 인코딩을 하기 때문입니다. 즉, 각 Red/Green/Blue 색깔 별로 2차원 행렬이 하나씩 필요합니다. 이 3가지 색깔을 나타내는 깊이 차원을 채널이라고도 합니다. 따라서 이미지 데이터는 3개의 채널로 이루어져 있습니다. (한편 컨브넷의 층에서는 더 많은 채널을 사용해 피쳐를 나타내며 이를 피쳐 맵이라고 합니다. 자세한 설명은 뒤에 이어집니다.)
이렇게 한 장의 이미지는 3차원 데이터로 나타낼 수 있습니다. 그런데 컨브넷 트레이닝 과정에서는 여러 장의 이미지를 사용하는 경우가 일반적입니다. 결과적으로 우리가 가진 이미지 데이터는 3차원 데이터의 어레이, 즉 4차원 텐서가 되는 것 입니다.
컨브넷 정의
컨볼루션의 어원은 라틴어 convolvere이고 그 뜻은 두 가지를 같이 돌돌 마는 행동을 의미합니다. 수학에서 컨볼루션은 두 가지 함수가 얼마나 겹치는지를 적분을 이용해 측정하는 것 입니다. 두 함수를 하나로 합치는 것이라고 이해해도 됩니다.
이 링크의 애니메이션을 보면 더욱 정확히 이해할 수 있습니다. 링크의 애니메이션은 x축 방향으로 함수 f(붉은 색)과 함수 g(파란 색)가 얼마나 겹치는지를 컨볼루션을 통해 구하는 과정입니다. 그리고 그 결과가 초록색 함수입니다. 두 함수가 얼마나 겹치는지를 측정하기 위해 우선 빨간색 함수 f를 고정시키고 파란색 함수 g를 x축으을 따라 이동시키면서 두 함수를 곱해준 것 입니다.
컨볼루션 네트워크에서, 우리는 이미지를 고정시키고 필터를 이동해가면서 이미지를 쭉 훑습니다. 그리고 훑어가면서 각 위치에서 행렬의 성분끼리 곱해주는 것이 컨브넷의 컨볼루션 과정입니다. Andrej Karpathy의 애니메이션을 보시면 더욱 정확히 이해할 수 있습니다. 링크의 “Convolution Demo”를 참고하십시오.
컨브넷에서는 하나의 이미지에 여러 가지 다양한 필터를 컨불루션 하는데, 각 필터는 서로 다른 모양을 잡아내는 역할을 합니다. 초기 단계의 컨볼루션 층에서는 수평선, 수직선, 대각선 등 단순한 모양을 잡아냅니다. 그리고 그 정보를 모으면 이미지의 아웃라인을 그려낼 수 있습니다.
이렇게 다양한 종류의 필터를 이용하면 이미지의 피쳐맵을 만들 수 있습니다. 피쳐맵이란 말 그대로 어디에 어떤 피쳐가 있는지 지도를 그리는 것 입니다. 예를 들어, 수평선을 잡아내는 필터를 사용한 피쳐맵은 각 이미지에서 어디에 수평선이 있는지를 나타내는 피쳐맵이 됩니다.
(이 작동 방식은 RBM과 매우 다릅니다. RBM은 이미지 전체를 보고 피쳐를 잡아내는 반면 컨브넷은 이미지를 작은 부분으로 나누어 피쳐를 뽑아냅니다.)
즉, 컨브넷은 이미지 위에서 특정한 모양을 검색한다고 할 수 있습니다. 작은 돋보기를 들고 큰 이미지를 위에서 아래로, 왼쪽에서 오른쪽으로 차근차근 훑어 나가는 과정을 생각해보십시오. 그리고 그 돋보기로 수직선 찾아 다닌다고 생각해보십시오. 즉 작은 수직선 전문 필터로 이미지 전체를 쭉 훑어 나가는 것 입니다.
그리고 수직선이 발견되면 그 결과를 피쳐맵에 반영합니다. 즉, 피쳐맵에는 어디에서 수직선이 발견되었는지를 기록합니다. 마치 보물지도에서 어디에 보물이 있는지를 점으로 찍어놓는 것 처럼 말입니다. 그리고 컨브넷은 수직선, 수평선, 대각선 작업에 필요한 다양한 모양을 찾아서 각각을 피쳐맵에 저장합니다.
이렇게 모든 위치에서 다양한 필터로 컨볼루션을 수행하기 때문에 컨브넷의 연산량은 꽤 많은 편입니다.
컨볼루션 층 하나를 통과하고 나면, 비선형 함수를 하나 거치게 됩니다. 하이퍼탄젠셜(tanh) 함수나 *ReLU(Rectified Linear Unit) 등이 이 비선형 함수에 해당합니다. 이 비선형 함수는 입력 데이터를 -1에서 1 사이의 값으로 압축해주는 역할을 합니다. (ReLU의 경우 조금 다르게 이를 수행합니다.)
컨볼루션과 컨볼루션 층
우선 컨브넷이 이미지를 처리하는 방식은 사람이 이미지를 보는 것과는 조금 다르다는 것을 알아야 합니다. 컨브넷이 이미지를 어떻게 보는지 설명드리겠습니다.
컨브넷은 이미지를 부피가 있는 3차원의 직육면체로 봅니다. 위에서 설명드렸듯이 이는 이미지 데이터가 3차원 행렬로 저장되기 때문입니다. 우리가 보는 이미지는 3개 채널의 R, G, B값을 합친 색깔이지만 데이터에서는 이를 따로 저장해야 하는 것 입니다. 최초에 컨브넷이 보는 이미지는 3장의 이미지를 포개놓은 형태입니다.
이미지의 너비와 높이는 가로/세로에 있는 이미지의 픽셀 수가 됩니다. 그리고 깊이, 혹은 채널 수는 3개가 됩니다.
이미지가 컨볼루션 층을 통과하면 우리는 이 입력/출력 데이터의 부피를 따져볼 수 있습니다. 일반적으로 30x30x3과 같이 가로x세로x깊이(채널)의 형태로 이 부피를 표기합니다. 그리고 데이터의 부피는 층을 통과할 때 마다 달라지는 경우가 많이 있습니다.
앞으로 각 층을 거칠때마다 이미지의 부피가 변하는데 이 숫자를 눈여겨보시기 바랍니다.
정리하면, 이미지 데이터에서 행렬의 각 성분은 (R,G,B)의 세기를 표현하는 벡터로 이루어져 있습니다.
이 (R,G,B)값은 컨볼루션 네트워크의 입력 값이 됩니다. 즉 컨볼루션 네트워크는 이 이미지를 보게 됩니다. 이 입력 데이터도 피쳐 중에서 네트워크가 감지하는 감응 피쳐라고 생각할 수도 있습니다. 그리고 일반적인 뉴럴넷과 마찬가지로 컨브넷은 이 숫자를 보고 이미지를 분류하는데 필요한 의미있는 신호를 감지하는 작업을 합니다.
컨브넷은 보통 이미지의 일부분을 정방형으로 잘라서 (이 잘린 부분을 패치라고 함) 필터에 통과시킵니다. 필터는 패치와 같은 크기입니다. 필터는 때론 커널이라고 불리기도 하는데 SVM에서 사용하는 커널과 같은 의미입니다. 즉, 이 필터는 픽셀에서 (혹은 피쳐맵에서) 원하는 패턴을 찾아줍니다.
이 애니메이션은 Andrej Karpathy가 만든 컨볼루션 데모입니다.*
30x30의 행렬(이미지)와 3x3의 행렬(필터)을 상상해 보십시오. 즉, 이 필터는 이미지의 1/3 길이로 된 필터입니다.
이제 이미지에 필터를 곱하려고 합니다. 이 곱(dot product)은 행렬곱이 아니라 성분끼리 곱하는 곱셈(element-wise multiplication)이라는 점을 유의하세요. 따라서 만일 두 행렬이 같은 위치에서 큰 값을 가지고 있다면 그 위치의 계산 결과도 큰 값이 나올 것입니다 (100x100). 반대로 둘 중 하나만 값이 크다면 작은 결과가 나오고 (100x1), 둘 다 작다면 더욱 더 작은 값이 나오게 됩니다 (1x1). 그러므로 특정한 값을 갖는 필터를 이용하면 어떤 위치에서 이미지의 픽셀 패턴이 필터와 얼마나 비슷한지를 구할 수 있습니다. 이는 상관계수(correlation)을 구하는 과정과도 같습니다.
예를 들어 우리의 필터가 수평선 패턴이라고 생각해봅시다. 가장 쉬운 예는 [[0,0,0],[1,1,1],[0,0,0]] 필터입니다. 맨 위와 아래 행은 작은 값을, 가운데 행은 큰 값을 갖는 행렬은 수평선 패턴 필터로 작동하게 됩니다. 이제 이 필터를 왼쪽 위에서부터 오른쪽 아래까지 쭉 이미지를 훑어 내려온다고 생각해 보십시오. 이렇게 훑어 내려올 때, 한 칸씩 옮겨가며 곱셈을 수행할 수도 있지만 더 여러 칸씩 옮겨가며 곱셈을 수행하기도 합니다. 이렇게 필터를 몇 칸씩 옮겨 가는지를 stride라고 부릅니다. 예를 들어 stride=2라고 지정한 경우에 두 칸씩 옮겨가며 곱셈을 수행합니다.
자리를 옮겨갈때마다 곱셈을 수행하고, 그 결과를 액티베이션 맵(activation map)에 저장합니다. 따라서 활동 맵의 크기는 가로/세로로 곱셈을 수행한 횟수와 같습니다. stride값이 크면 액티베이션 맵의 크기가 작아지고, stride가 작으면 맵의 크기가 커집니다. 이 내용은 컨브넷을 디자인할 때 아주 중요합니다. stride가 작을 수록 많은 곱셈을 수행해야 하는데, 컨볼루션 네트워크는 연산량이 많이 필요하기 때문에 이 값을 적절히 조절해 주어야 합니다.
만일 stride가 3이라면 이 필터는 이미지의 1-3행에서 곱셈을 수행한 뒤 이미지의 4-6행으로 옮겨서 다시 곱셈을 수행할 것 입니다. 결과적으로 입력 이미지는 30x30이었지만 출력으로 나온 액티베이션 맵은 10x10 행렬이 됩니다. 위에서 설명한 수평선 필터는 R, G, B채널 3개를 모두 훑으며 수평선이 있는지를 각각 계산합니다. 그리고 최종적으로 이 수평선 필터가 만드는 한 액티베이션 맵은 R, G, B를 훑은 결과의 평균이 됩니다.
이미지는 수평선 뿐만 아니라 다양한 방향의 선으로 이루어져 있습니다. 따라서 수평선 필터 뿐만 아니라 다른 모양의 필터도 사용해야 합니다. 예를 들어 컨브넷이 96개의 다른 패턴을 조사해서 96개의 액티베이션 맵을 만들도록 디자인 할 수 있습니다. 즉 최종 결과는 10x10x96 행렬이 됩니다. 아래 그림을 참고하십시오.
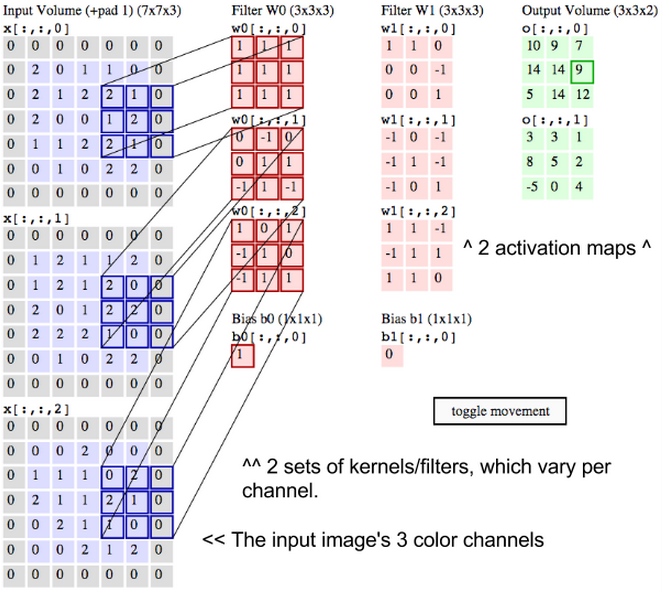
그동안 컨볼루션에 대해 자세히 다뤘습니다. 내용을 잘 이해했으면 컨볼루션을 복잡한 개념이 아니라 그저 두 행렬의 성분끼리 곱하는 것으로 편하게 생각하면 됩니다.
이미지는 데이터의 크기가 크기 때문에 이미지를 처리할 때에는 늘 연산량에 신경써야 합니다. 컨볼루션 네트워크는 여러 가지 방법을 사용해 이미지의 크기를 줄입니다. 위의 컨볼루션 네트워크에서 stride를 통해 결과로 나오는 행렬(액티베이션 맵)의 크기를 줄이는 방법을 소개했습니다. 또 다른 방법은 다운 샘플링입니다.
맥스 풀링/다운 샘플링
이 층은 맥스 풀링(max pooling), 다운 샘플링(downsampling), 서브 샘플링(subsampling) 등 여러 이름을 가지고 있습니다. 위의 컨볼루션 층의 결과로 나온 액티베이션 맵은 일반적으로 다운 샘플링 층의 입력이 됩니다. 다운 샘플링 과정은 컨볼루션 층과 비슷하게 작은 패치 단위의 연산을 여러 번 수행하도록 되어있습니다. 컨볼루션 층과 달리 여기에선 행렬 곱보다 훨씬 간단한 작업을 합니다. 맥스 풀링은 이미지 패치에서 최대값을 결과로 출력합니다.
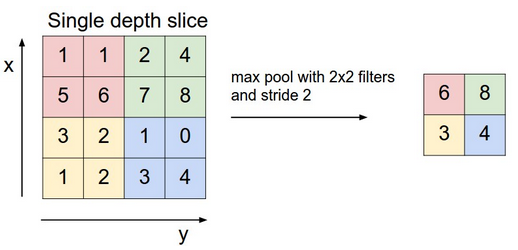 위의 이미지는 Andrej Karpathy가 만든 이미지입니다.
위의 이미지는 Andrej Karpathy가 만든 이미지입니다.
따라서 패치 내에서 제일 큰 액티베이션 값만 결과로 남고 나머지는 버려집니다. 컨볼루션의 역할을 생각하면, 패치 내의 여러 위치 중에서 필터의 패턴과 가장 잘 일치하는 부분만 살아남게 됩니다.
결과적으로 최대값이 아닌 나머지 모든 정보가 버려지고, 이를 대체하는 다른 방법도 많이 연구되고 있습니다. 어쨌든 이 다운 샘플링 과정을 통해 데이터의 크기가 작아지므로 메모리와 연산량에서 큰 이득을 보게 됩니다.
여러 층을 조합하는 방법
아래 그림은 컨볼루션 네트워크 전체를 시각화한 것 입니다.
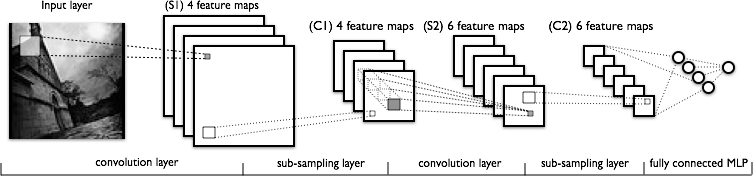
왼쪽부터 구성 요소를 살펴보겠습니다.
- 입력 이미지가 들어오면 필터를 통과합니다. 위의 그림에서는 액티베이션 맵이 아닌 피쳐맵으로 표시되었습니다.
- 필터가 여러 종류이기 때문에 액티베이션 맵도 여러 종류의 맵을 쌓게됩니다.
- 그리고 그 맵은 다운 샘플링 과정에서 더 작게 압축됩니다.
- 그 결과가 C1에 해당합니다.
- 그 뒤를 새로운 컨볼루션 층과 다운 샘플링 층이 잇게 되고 최종적으로 C2가 나옵니다.
- 마지막으로 이렇게 나온 피쳐맵은 일반적인 인공 신경망의 층(Fully-connected layer)로 들어갑니다. 그 결과로 분류하려는 라벨 하나당 노드 하나씩 값을 출력합니다.
여러 단계를 지날수록 처음 이미지에 있던 정보는 손실되고, 대신 특정 패턴이 어디에 존재하는지만 남게 됩니다. 이 과정이 직관적이지 않더라도 자세히 살펴보시기 바랍니다.
DL4J 예제 코드
아래 예제를 참고하면 Deeplearning4j에서 어떻게 컨브넷을 사용할 수 있는지 알 수 있습니다.
그 외 참고 자료
- 뉴욕대학교 교수 겸 페이스북 AI연구소장인 얀 르쿤은 컨볼루션 네트워크의 선구자 입니다.
- Andrej Karpathy의 스탠포드 강의자료 컨볼루션 파트는 정말 훌륭합니다. 일독을 강력히 권합니다. 파이썬으로 된 연습문제도 있습니다.
- Deeplearning4j의 컨볼루션 테스트 코드도 참고하십시오.
- DL4J의 컨볼루션 네트워크를 직접 실행해보려면 저희의 예제 코드를 실행해보십시오. 예제 코드를 실행하려면 퀵 스타트 가이드를 먼저 참고하십시오.
- DL4J의 RNN 소개 자료,
- DL4J의 RBM 소개 자료,
- DL4J의 인공 신경망 소개자료도 참고하십시오.