Word2Vec
내용
- 소개
- 신경망과 Word Embeddings
- 재미있는 Word2vec 결과
- 예제 코드
- DL4J에서 Word2vec 구조
- 준비, 데이터 로딩 및 학습
- 코드 예제
- 문제 해결 및 Word2Vec 튜닝하기
- Word2vec 이용 사례
- 외국어
- GloVe (Global Vectors) & Doc2Vec
Word2Vec 소개
Word2vec은 텍스트를 처리하는 인공 신경망이며 두 개의 층으로 구성되어 있습니다. Word2vec은 말뭉치(corpus)를 입력으로 받아서 말뭉치의 단어를 벡터로 표현 하는 방법을 찾는데, 이 벡터의 값은 말뭉치에서 단어가 가지는 의미나 역할을 잘 표현해주는 값이어야 합니다. 이렇게 단어의 의미와 맥락을 고려하여 단어를 벡터로 표현한 것을 word embeddings라고 합니다. Word2vec은 심층 신경망은 아니지만 심층 신경망은 전처리 단계로 많이 쓰입니다.
Word2vec의 응용 분야는 매우 다양합니다. 가장 흔한 예는 텍스트로 된 문장을 이해하는 것 입니다. 그 외에도 word2vec의 구조는 DNA 염기서열, 코드, 음악 재생목록, 소셜 미디어에서 사람들의 관계망 (graph)를 이해하는데 사용합니다. Deeplearning4j는 Spark 기반의 Java에서 GPU 연산 Scala을 위한 분산 구조 Word2vec을 제공합니다.
Word2vec을 이용하면 단어간 유사성을 구할 수 있습니다. 원래 word embeddings의 목적이 유사한 단어일 수록 가까운 거리에 위치하도록 각 단어에 해당하는 벡터 값을 찾는 것 입니다. 이 학습은 사람이 관여하지 않으며 말뭉치 데이터만을 사용합니다.
데이터의 양이 충분하면 Word2vec은 단어의 의미를 꽤 정확하게 파악합니다. 그리고 이를 이용하면 단어의 뜻 뿐만 아니라 여러 단어의 관계를 알아냅니다. 예를 들어 단어의 관계를 이용해 ‘남자’:’소년’ = ‘여자’:x 같은 관계식을 주면 x=’소녀’라는 답을 구할 수 있습니다. 단어 뿐만 아니라 더 큰 단위의 텍스트인 문장이나 문서를 분류하는데에도 Word2vec을 사용합니다. 예를 들어 문서를 군집화한 뒤에 결과를 이용하면 검색 엔진에서 문서의 분야별 검색(과학, 법률, 경제 등)이나 문장의 감정 분석, 추천 시스템을 만들 수 있습니다.
정리하면, Word2vec은 각 단어마다 단어에 해당하는 벡터를 구해줍니다. 이 벡터를 다시 심층 신경망에 집어넣어서 추가적인 일을 할 수도 있고 단어의 유사성 등 관계를 파악할 수 있습니다.
유사성을 구하는 방법은 여러 가지가 있습니다. 흔히 쓰이는 방법은 코사인 유사도입니다. 코사인 유사도는 두 벡터의 각도를 측정하는 것으로 각도가 같은 경우, 즉 두 벡터가 이루는 각이 0도인 경우엔 유사도의 최대값인 1.0이 나옵니다. 그리고 가장 유사도가 낮은 경우는 두 벡터의 각도가 90도가 되는 경우입니다 (실제로 90도가 나오는 경우는 거의 없습니다). 예를 들어 ‘스웨덴’과 ‘노르웨이’의 유사성을 구하면 0.760124 라는 제법 높은 유사도가 나올 것 입니다.
아래에 Word2vec을 이용해 구한 단어의 embeddings 중에서 ‘스웨덴’과 가장 거리가 가까운, 즉 가장 유사한 단어를 모아놓았습니다.
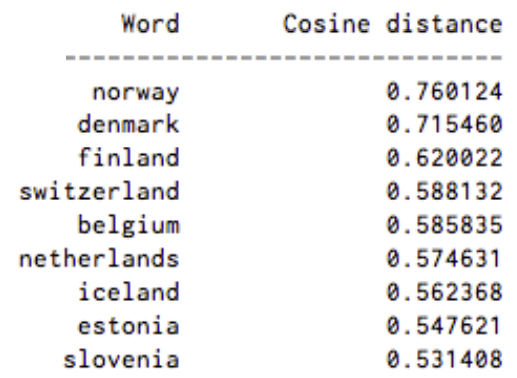
스칸디나비아 반도의 여러 국가와 기타 북유럽, 독일계 나라가 가장 가까운 단어 9개를 차지했습니다.
Neural Word Embeddings
이렇게 뉴럴 네트워크를 이용해 word embeddings를 구하는 것을 neural word embeddings이라고 합니다.
즉, word embeddings은 사람의 언어를 컴퓨터의 언어로 번역하는 것 입니다.
단어를 같은 의미지만 다른 표현인 벡터로 바꿔준다는 점에서 Word2vec은 오토인코더와 비슷한 면이 있습니다. 하지만 RBM(restricted Boltzmann machines)의 재구성(reconstruction) 과정과 Word2vec의 학습 과정은 좀 다릅니다. Word2vec은 입력한 말뭉치의 문장에 있는 단어와 인접 단어의 관계를 이용해 단어의 의미를 학습합니다.
Word2vec의 학습 방법은 두 종류가 있습니다. CBOW(Continous Bag Of Words) 방식은 주변 단어가 만드는 맥락을 이용해 타겟 단어를 예측하는 것이고 skip-gram은 한 단어를 기준으로 주변에 올 수 있는 단어를 예측하는 것 입니다. 대규모 데이터셋에서는 skip-gram이 더 정확한 것으로 알려져있으며 저희도 이 방식을 이용합니다.
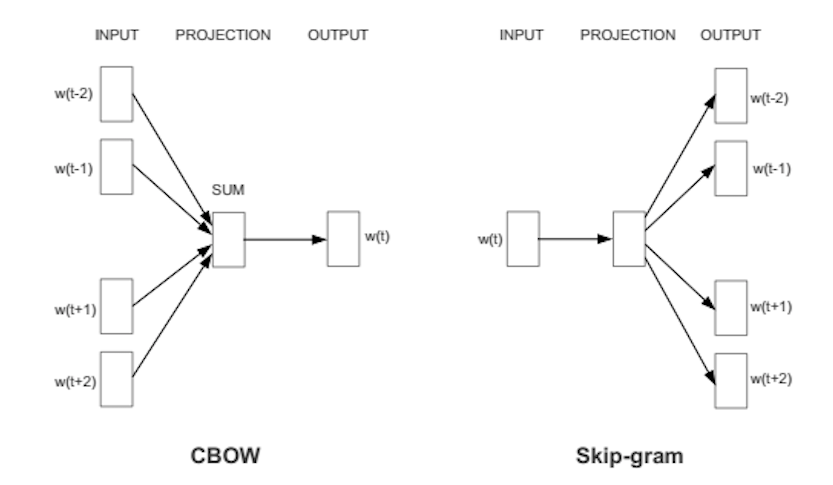
Word2vec의 학습 과정은 큰 틀에서 일반적인 인공 신경망의 학습과 비슷합니다. 한 단어에 이미 할당된 벡터, 즉 word embedding이 있다고 가정하면 이 값을 이용해 주변 문맥을 얼마나 정확하게 예측하는지 계산합니다. 그리고 정확도가 좋지 못한 경우, 즉 추가적인 조정이 필요한 경우에 오차에 따라 벡터의 값을 업데이트합니다. 즉, 학습 과정에서 한 단어를 기준으로 단어 주변의 문맥을 참고하여 현재 embedding 벡터가 얼마나 정확한지, 오차의 값은 어느 정도인지를 알아냅니다. 만일 어떤 두 단어가 비슷한 문맥에서 꾸준하게 사용될 경우 두 단어의 벡터 값은 비슷하게 됩니다.
전체 차원이 500차원일 경우 이 embedding 벡터는 500차원 공간에 있는 점 하나에 해당합니다. 3차원 이상의 공간은 머릿속에서 상상하기 어렵지만 word embedding은 보통 수백차원의 공간을 사용합니다.
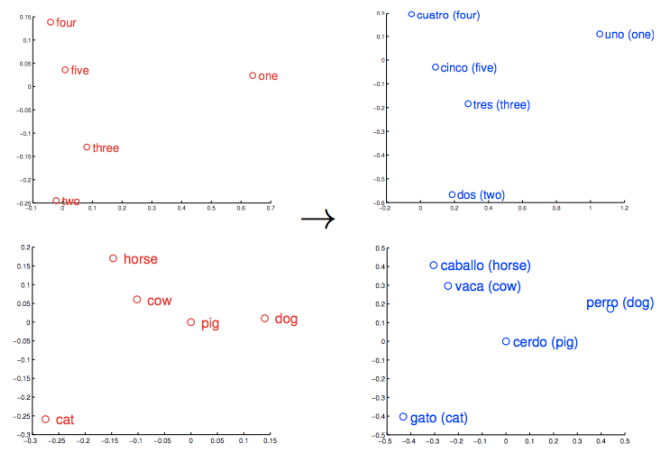
학습이 잘 완료되었다면 이 고차원 공간에서 비슷한 단어는 근처에 위치하게 됩니다. 예를 들어 나무의 종류인 oak, elm 및 birch 는 비슷한 곳에 모이게 됩니다. 또 의미에 유사성이 있는 war(전쟁), conflict(갈등) 및 strife(불화)는 다른 위치에 모이게 됩니다.
비슷한 물체나 개념은 가까이에 위치합니다. 그리고 단어의 상대적인 의미와 관계 또한 이 공간의 관계에 잘 변환됩니다. 이 관계를 이용하면 유사성을 넘어서 더 복잡한 일을 할 수 있습니다. 이를 테면 아래 예제와 같은 일 입니다.
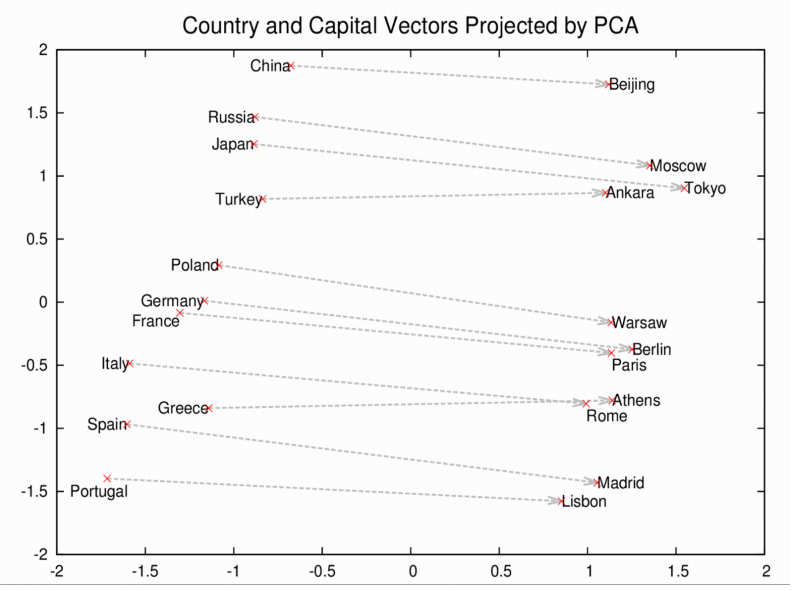
이 예제에서 두 가지를 이해하시면 됩니다. 로마, 파리, 베를린, 베이징은 전부 나라의 수도이며 비슷한 의미와 맥락에서 쓰이기 때문에 가까이 위치합니다. 뿐만 아니라, 벡터의 합과 차를 이용하면 재미있는 결과를 얻을 수 있습니다. 각 수도를 뜻하는 단어는 각 나라와 같은 관계에 있습니다. 즉 로마와 이탈리아, 베이징과 중국은 모두 수도와 국가의 관계이므로 각각에 로마-이탈리아와 베이징-중국의 벡터 공간에서의 관계도 유사하게 학습이 되어야 합니다. 실제로 Word2vec을 이용해 로마(의 embedding 벡터) - 이탈리아(의 embedding 벡터) + 중국(의 embedding 벡터)를 수행하면 베이징이 나옵니다. 왜냐하면 로마-이탈리아와 중국-베이징은 상대적으로 비슷한 벡터이기 때문입니다.
재미있는 Word2Vec 사용 결과
Word2vec을 이용한 다른 연산을 보겠습니다.
우선 더하기, 빼기, 등호 대신에 다른 기호를 사용하겠습니다. 수학에서 비례식은 1:2=5:10 으로 관계를 표현합니다. 이것과 유사하게 우리는 :와 ::를 사용합니다. ::은 등호(=)로 생각하시면 됩니다. 위의 예제에 적용하면, “로마에게 이탈리아가 있다면 베이징에겐?(정답은 중국)”의 표현을 로마:이탈리아::베이징:?? 으로 표현할 수 있습니다. 이렇게 하면 Word2vec이 적절한 단어를 골라 줍니다. 아래는 Word2vec이 고른 단어를 확률이 높은 순서대로 여러 개 나열했습니다.
왕:여왕::남자:[여자, 유괴 미수, 10대, 여자 아이]
//조금 이상한 단어도 있지만 대체로 어느 정도 이해할 수 있습니다.
중국:대만::러시아:[우크라이나, 모스코바, 몰도바, 아르메니아]
//지정학적 및 외교적 관계를 반영한 결과가 나왔습니다. 모스코바는 조금 이상하지만요.
집:지붕::성:[돔, 종탑, 첨탑, 총탑, 포탑]
무릎:다리::팔꿈치:[팔, 팔뚝, 척골]
뉴욕타임즈::슐츠버그::폭스:[머독, 처닌, 뱅크로프트, 아일즈]
//슐츠버그는 뉴욕 타임즈의 소유주 및 경영자
//머독은 폭스 뉴스의 소유주
//피처 너닌은 폭스 뉴스의 최고업무책임자(COO)였음
//로저 아일즈는 폭스 뉴스의 회장
//뱅크로프트가는 월스트리트 저널을 머독에게 판매함
사랑:무관심::공포:[무관심, 냉담, 수줍음, 무력함, 무반응]
도날드 트럼프:공화당::버락 오바마:[민주당, 공화당, 민주당지지자, 매캐인]
//오바마와 매캐인의 라이벌 관계를 생각하면 Word2vec이 트럼프와 공화당의 관계를 적대적인 관계로도 해석한다고 볼 수 있습니다.
원숭이:사람::공룡:[화석, 화석화, 빙하기포유류]
//인류는 화석화된 원숭이다? 인류는 원숭이의 잔재다? 인류는 원숭이의 대결에서 승리한 경쟁자이다? 다 조금씩 말이 됩니다.
건물:건축가::소프트웨어:[프로그래머]
이 결과는 구글 뉴스 데이터셋을 사용해 학습한 것이며 이 데이터셋은 DL4J에서 언제든지 import할 수 있습니다. 중요한 점은 Word2vec이 영어의 문법을 전혀 모르는 상태에서 이렇게 스스로 학습했다는 것 입니다. Word2vec은 아무런 언어 구조나 사전 없이 단시간에 엄청난 양의 단어를 학습합니다.
이번엔 다른 수식으로 Word2vec의 결과로 나온 embedding의 연산을 해봅시다. (자세한 설명은 아래에서 다룹니다.)
- 지정학적 개념: 이라크 - 폭력 = 요르단
- 구별, 차이점: 사람 - 동물 = 윤리
- 대통령 - 권력 = 수상
- 도서관 - 책 = 홀
- 비유: 주식 시장 ≈ 온도계
Word2vec에서 구한 유사 단어는 단어의 스펠링과 전혀 관계 없습니다. Word2vec은 단어의 의미를 기반으로 유사성을 구하며 결과적으로 단어를 고차원 공간 벡터를 이용해 나타냅니다.
예제 코드
DL4J에서 Word2vec 구조
Deeplearning4je는 자연어 처리 도구는 아래와 같습니다.
- SentenceIterator/DocumentIterator: 데이터 셋의 데이터로 쉽게 반복 작업을 할 수 있습니다.
SentenceIterator는 문자열(string)을 반환하고DocumentIterator는 문서의java.io.InputStream를 반환합니다. 가급적SentenceIterator을 사용하기를 권장합니다. - Tokenizer/TokenizerFactory: 텍스트를 토큰화 하는데 사용됩니다. 자연어 처리에서 보통 한 문장은 여러 토큰의 배열로 변환됩니다.
TokenizerFactory는 문장 하나를 위한 tokenizer의 인스턴스를 생성합니다. - VocabCache: 단어의 개수, 단어를 포함하고 있는 문서의 개수, 토큰의 개수와 종류, Bog-of-Words, 단어 벡터 룩업테이블(Look Up Table, 순람표)) 등 메타 데이터를 저장하는데 쓰입니다.
- Inverted Index: 단어가 발견된 위치를 메타 데이터에 저장합니다. 이 값은 데이터 셋을 이해하는데 사용할 수 있습니다. Lucene implementation[1]에 기반한 Lucene 색인이 자동으로 생성됩니다.
Word2vec은 여러 알고리즘으로 이루어져 있습니다. DL4J의 Word2vec은 Skip-Gram Negative Sampling을 사용해 구현했습니다.
Word2Vec 설정
Maven을 사용해 IntelliJ에 새 프로젝트를 만드십시오. 프로젝트를 만드는 자세한 방법은 저희의 퀵스타트 페이지를 참고하시기 바랍니다. 그리고 아래의 속성과 종속성(dependencies) 설정을 생성한 프로젝트의 루트 디렉토리에 있는 POM.xml 파일에 추가하십시오 (Maven의 버전은 여기서 확인할 수 있습니다. 최신 버전의 Maven 사용을 권장합니다.).
<properties>
<nd4j.version>0.4-rc3.9</nd4j.version> // check Maven Central for latest versions!
<dl4j.version>0.4-rc3.9</dl4j.version>
</properties>
<dependencies>
<dependency>
<groupId>org.deeplearning4j</groupId>
<artifactId>deeplearning4j-ui</artifactId>
<version>${dl4j.version}</version>
</dependency>
<dependency>
<groupId>org.deeplearning4j</groupId>
<artifactId>deeplearning4j-nlp</artifactId>
<version>${dl4j.version}</version>
</dependency>
<dependency>
<groupId>org.nd4j</groupId>
<artifactId>nd4j-native</artifactId>
<version>${nd4j.version}</version>
</dependency>
</dependencies>
데이터 불러오기
이제 적당한 이름으로 새로운 클래스를 생성하십시오. 그리고 raw_sentences.txt 파일에서 전처리 되기 전의 문장을 불러온 뒤 이 문장을 iterator에 넣은 뒤 모든 글자를 소문자로 변환하는 간단한 전처리를 수행합니다.
log.info("Load data....");
ClassPathResource resource = new ClassPathResource("raw_sentences.txt");
SentenceIterator iter = new LineSentenceIterator(resource.getFile());
iter.setPreProcessor(new SentencePreProcessor() {
@Override
public String preProcess(String sentence) {
return sentence.toLowerCase();
}
});
예제 파일이 아닌 다른 텍스트를 불러올 수도 있습니다.
log.info("Load data....");
SentenceIterator iter = new LineSentenceIterator(new File("/Users/cvn/Desktop/file.txt"));
iter.setPreProcessor(new SentencePreProcessor() {
@Override
public String preProcess(String sentence) {
return sentence.toLowerCase();
}
});
위의 코드에서는 ClassPathResource를 삭제하고 대신에 불러올 .txt 파일의 절대 경로를 LineSentenceIterator에 입력했습니다.
SentenceIterator iter = new LineSentenceIterator(new File("/your/absolute/file/path/here.txt"));
파일의 절대 경로를 추가하는 부분입니다.
데이터 토큰화 하기
Word2vec는 텍스트를 단어별로 받아들입니다. 따라서 위와 같이 불러온 텍스트는 단어 단위로, 그리고 단어도 다시 어근으로 변환해야 합니다. 토큰화를 잘 모르신다면 텍스트를 구성하는 최소 단위로 원자화했다고 이해하시면 됩니다.
// Split on white spaces in the line to get words
TokenizerFactory t = new DefaultTokenizerFactory();
t.setTokenPreProcessor(new CommonPreprocessor());
이렇게 하면 한 줄에 토큰 하나씩 결과를 출력합니다.
모델 학습하기
이제 데이터가 준비되었으므로 여러분께서는 Word2vec 신경망을 구성하고 토큰에서 공급하실 수 있습니다.
int batchSize = 1000;
int iterations = 3;
int layerSize = 150;
log.info("Build model....");
Word2Vec vec = new Word2Vec.Builder()
.batchSize(batchSize) //# words per minibatch.
.minWordFrequency(5) //
.useAdaGrad(false) //
.layerSize(layerSize) // word feature vector size
.iterations(iterations) // # iterations to train
.learningRate(0.025) //
.minLearningRate(1e-3) // learning rate decays wrt # words. floor learning
.negativeSample(10) // sample size 10 words
.iterate(iter) //
.tokenizerFactory(tokenizer)
.build();
vec.fit();
이 코드를 보면 굉장히 많은 하이퍼파라미터(파라미터를 정하는 파라미터)를 설정합니다. 이에 대해 간략히 설명드리겠습니다.
- batchSize는 한 하드웨어(GPU나 CPU)에서 iteration 한번에 처리하는 단어의 양입니다. batchSize가 크면 GPU의 최적화된 병렬 프로세싱 덕분에 빠르게 진행이 되지만 한번에 많은 단어를 보기 위해선 많은 메모리가 필요합니다.
- minWordFrequency는 말뭉치에서 유효한 단어로 인정받는데 필요한 최소 단어 개수입니다. 즉, 이 값보다 적게 나타난 단어는 없는 단어로 간주합니다. 이렇게 하는 이유는 우선 단어의 embedding이 잘 학습되려면 단어의 용례가 여러 개 필요하기 때문입니다. 또, 잘 나타나지 않는 희귀한 단어를 제외해주면 메모리와 연산량도 효율적으로 사용하게 됩니다.
- useAdaGrad - Adagrad는 학습 과정의 최적화에 쓰이는 기법 중 하나입니다.
- layerSize는 단어 벡터의 차원입니다. 예를 들어 500차원 벡터로 단어를 표현하려면 이 값을 500으로 설정하면 됩니다.
- iterations 이 값은 전체 데이터에 몇 회의 학습을 반복할 것인지를 정합니다. 횟수가 부족하면 데이터에서 추출 가능한 정보를 다 쓰지 않고 학습을 끝내게 되므로 성능이 떨어집니다. 그러나 너무 많은 반복을 하는 것은 비효율 적입니다. 이 값은 상황에 따라 다르기 때문에 우선 학습을 해보고 결과를 관찰하며 조절합니다.
- learningRate(학습 속도)는 매 반복 학습마다 일어나는 업데이트의 크기와 관련된 값입니다. 이 값이 너무 작으면 학습 속도가 너무 느리며, 반대로 너무 크면 정밀하게 학습을 하지 못하거나 심지어 학습에 실패하고 완전히 발산할 수도 있습니다.
- minLearningRate는 학습 속도의 하한선입니다. 자동으로 학습 비율을 정하는 경우에 너무 작은 값이 되지 않도록 해줍니다.
- iterate은 데이터의 여러 배치(batch, 데이터를 쪼갠 단위) 중 어떤 배치에서 현재 학습중인지를 알려줍니다.
- tokenizer는 배치에 있는 단어를 학습 과정에 공급합니다.
- vec.fit() - 구성이 완료되면 이 명령어를 써서 학습을 시작합니다.
Word2vec 모델 학습 결과 평가하
아래 코드는 얼마나 모델이 학습이 잘 되었는지를 확인하는 코드입니다.
// Write word vectors
WordVectorSerializer.writeWordVectors(vec, "pathToWriteto.txt");
log.info("Closest Words:");
Collection<String> lst = vec.wordsNearest("day", 10);
System.out.println(lst);
UiServer server = UiServer.getInstance();
System.out.println("Started on port " + server.getPort());
//output: [night, week, year, game, season, during, office, until, -]
vec.similarity("word1","word2")함수는 두 단어의 유사도를 코사인 유사성을 이용해 계산하고 그 결과를 반환합니다. 비슷한 단어일수록 1에 가까운 값이. 다른 단어일수록 0에 가까운 값이 나옵니다. 예를 들면 아래와 같습니다.
double cosSim = vec.similarity("day", "night");
System.out.println(cosSim);
//output: 0.7704452276229858
아래의 vec.wordsNearest("word1", numWordsNearest)는 유사성이 높은 몇 가지 단어를 출력합니다. 이를 이용해 학습이 잘 되었는지 확인할 수 있습니다. wordsNearest의 두 번째 입력변수는 출력할 단어의 개수입니다. 예를 들면 아래의 코드는 man과 제일 비슷한 단어 10개를 출력합니다.
Collection<String> lst3 = vec.wordsNearest("man", 10);
System.out.println(lst3);
//output: [director, company, program, former, university, family, group, such, general]
모델 시각화
Word embeddings 벡터의 차원을 확 줄여서 시각화 하는 방법이 있습니다. TSNE(T-SNE라고도 표기)라는 방법입니다.
log.info("Plot TSNE....");
BarnesHutTsne tsne = new BarnesHutTsne.Builder()
.setMaxIter(1000)
.stopLyingIteration(250)
.learningRate(500)
.useAdaGrad(false)
.theta(0.5)
.setMomentum(0.5)
.normalize(true)
.usePca(false)
.build();
vec.lookupTable().plotVocab(tsne);
저장하기, 저장한 모델 불러서 사용하기
설계 및 학습된 모델은 보통 저장하는 방법은 객체 직렬화(serialization) utils입니다 (Java의 직렬화는 객체를 series의(직렬화된) 바이트로 전환하는 Python pickling과 유사합니다).
log.info("Save vectors....");
WordVectorSerializer.writeFullModel(vec, "pathToSaveModel.txt");
위의 코드는 모델이 저장된 폴더에 words.txt를 저장합니다. 이 텍스트 파일은 한 줄에 하나의 단어(의 벡터)를 적어 놓은 형태가 됩니다.
이렇게 불러온 벡터는(vec) 아래와 같이 다시 사용하면 됩니다.
Collection<String> kingList = vec.wordsNearest(Arrays.asList("king", "woman"), Arrays.asList("queen"), 10);
Word2vec의 벡터를 이용한 가장 유명한 예제는 “king - queen = man - woman” 및 그 확장인 “king - queen + woman = man” 입니다.
위의 예제는 벡터 연산 king - queen + woman의 결과에 가장 가까운 10개의 단어를 골라줍니다. 정상적으로 학습이 되었다면 그 단어엔 man이 있을 것 입니다. 이 예제에서 wordsNearest의 첫 번째 입력 변수는 king과 woman, 두 번째 입력 변수는 queen입니다. 일반적인 규칙을 생각해보면, 위의 식 king - queen + woman의 단어 중 부호가 +인 단어를 첫 번째 입력 변수로, 부호가 -인 단어를 두 번째 입력 변수로 넣으면 됩니다. 마지막으로 들어간 입력변수 10은 총 10개의 단어르 출력하라는 의미입니다. 이 코드를 import java.util.Arrays;파일 상단에 추가하십시오.
어떤 단어든지 연산은 가능합니다. 하지만 단어의 의미를 잘 반영하는 식을 세워야 말이 되는 결과를 얻을 수 있습니다.
아래 코드는 벡터를 다시 메모리에 올립니다.
Word2Vec word2Vec = WordVectorSerializer.loadFullModel("pathToSaveModel.txt");
그리고 나면 Word2vec을 룩업 테이블로 쓸 수 있습니다.
WeightLookupTable weightLookupTable = wordVectors.lookupTable();
Iterator<INDArray> vectors = weightLookupTable.vectors();
INDArray wordVector = wordVectors.getWordVectorMatrix("myword");
double[] wordVector = wordVectors.getWordVector("myword");
만일 검색한 단어가 모델의 어휘 목록에 없으면 0을 반환합니다.
Word2vec 학습된 모델 불러오기
저희는 간편한 성능 테스트를 위해 구글 뉴스 말뭉치 모델을 아마존 S3에 호스팅하고 있습니다. 학습에 시간이 오래 걸리거나 여의치 않은 경우엔 이 모델을 다운받아서 사용하시면 됩니다.
만일 C vectors나 Gensimm으로 학습한 모델을 원한다면 아래의 코드를 참고하십시오.
File gModel = new File("/Developer/Vector Models/GoogleNews-vectors-negative300.bin.gz");
Word2Vec vec = WordVectorSerializer.loadGoogleModel(gModel, true);
import java.io.File;을 import한 패키지에 추가하는 것을 잊지 마십시오.
대형 모델들과 작업 시 힙 메모리를 조절해야 합니다. 구글 모델은 대략 10G의 메모리가 필요한데 JVM은 가본적으로 256 MB의 공간을 할당하기 때문입니다. bash_profile에서 설정을 하거나 (저희의 Troubleshooting 섹션을 참고하세요) IntelliJ 설정을 바꿔주면 됩니다.
//아래 메뉴를 실행한 뒤,
IntelliJ Preferences > Compiler > Command Line Options
//아래 내용을 붙여넣으세요.
-Xms1024m
-Xmx10g
-XX:MaxPermSize=2g
N-grams & Skip-grams
학습 과정에서 단어는 우선 하나의 벡터에 할당이 되고, 그 단어를 중심으로 전후의 몇 단어를 같이 읽습니다. 이렇게 연속된 n개의 단어를 통째로 n-그램이라고 합니다. n-그램의 특수한 케이스로, 단어를 띄어쓰기 기준으로 하나의 단어를 하나의 개체로 보는 것을 유니그램(unigram, n=1), 두 개씩 이어서 생각하는 것을 바이그램(bigram, n=2)이라고 합니다. 즉 n-그램은 문서를 n개의 연속된 단어 단위로 자른 것 입니다. 예를 들어 문장이 ‘하나의 벡터에 할당이 된다.’라면 여기에는 4개의 유니그램 ‘하나의’, ‘벡터에’, ‘할당이’, ‘된다’이 있는 것 입니다 (토큰화하는 과정은 생략하였습니다). 바이그램으로 표현하면 ‘하나의 벡터에’, ‘벡터에 할당이’ ‘할당이 된다’ 이렇게 3개의 바이그램을 만들 수 있습니다. 스킵그램(skip-gram)은 n-그램에서 기준이 되는 단어를 제외한 것 입니다.
DL4J가 구현한 스킵그램은 Mikolov가 발표한 방법으로, CBOW보다 더 정확한 것으로 알려져있습니다.
말뭉치에서 추출한 n-그램을 Word2vec 신경망에 공급하면 단어의 벡터값을 찾아줍니다.
코드 예제
이제 여러분께서는 Word2Vec 코드의 설정 방법을 대략 이해하고 계실 것 입니다. 이제 이 Word2vec이 어떻게 DL4J의 다른 API에서 쓰이는지를 보여주는 예제를 참고하시기 바랍니다.
퀵 스타트 가이드의 설명을 참고해 IDE를 설정하셨다면, 이제 IntelliJ에서 이 예제를 열고 실행해보십시오. 만약 학습에 사용한 말뭉치에 없는 단어를 입력에 넣으면 모델은 null값을 반환할 것 입니다.
문제 해결 및 Word2Vec 튜닝하기
질문: 아래와 같은 trace 메시지가 뜹니다.
java.lang.StackOverflowError: null
at java.lang.ref.Reference.<init>(Reference.java:254) ~[na:1.8.0_11]
at java.lang.ref.WeakReference.<init>(WeakReference.java:69) ~[na:1.8.0_11]
at java.io.ObjectStreamClass$WeakClassKey.<init>(ObjectStreamClass.java:2306) [na:1.8.0_11]
at java.io.ObjectStreamClass.lookup(ObjectStreamClass.java:322) ~[na:1.8.0_11]
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1134) ~[na:1.8.0_11]
at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1548) ~[na:1.8.0_11]
답: Word2vec이 저장된 디렉토리, 즉 IntelliJ 프로젝트 홈 디렉터리나 커맨드 라인에 Java를 실행한 디렉토리에 가면 아래 같은 형식의 디렉토리가 여러 개 있을 것 입니다.
ehcache_auto_created2810726831714447871diskstore
ehcache_auto_created4727787669919058795diskstore
ehcache_auto_created3883187579728988119diskstore
ehcache_auto_created9101229611634051478diskstore
우선 프로그램을 종료한 뒤 이 폴더를 삭제하고 다시 한 번 시도해 보십시오.
질문: 텍스트에 분명 있는 단어인데 Word2vec 결과에는 없습니다.
답: Word2Vec 모델의 .layerSize() 함수로 레이어의 크기를 키워보십시오.
Word2Vec vec = new Word2Vec.Builder().layerSize(300).windowSize(5)
.layerSize(300).iterate(iter).tokenizerFactory(t).build();
질문: 어떻게 하면 제 데이터를 로딩하나요? 왜 이렇게 학습이 오래 걸리나요?
답: 만일 여러분이 입력한 데이터가 단 하나의 문장으로 이루어져 있다면 학습하는데 시간이 아주 오래 걸립니다. 왜냐하면 Word2vec은 문장 단위로 작동하기 때문입니다. (GloVe알고리즘은 문장 단위가 아니라 말뭉치 전체를 보기 때문에 이런 문제가 없습니다.) 따라서 데이터셋엔 문장과 문장 사이에 마침표가 잘 찍혀있어야 합니다. 만일 마침표를 생략한 데이터셋을 가지고 있다면 예를 들어 10,000단어를 하나의 문장으로 보도록 임의로 지정할 수 있습니다. 이렇게 하려면 SentenceInterator와 Tokenizer를 별도로 수정해야 합니다.
질문: 전부 시키는대로 했는데도 결과가 이상합니다.
답: 혹시 OS가 Ubuntu인가요? Ubuntu는 직렬화된 데이터 로딩에 문제가 있습니다. 이 부분은 수정이 어려우니 다른 종류의 Linux를 사용하길 권장합니다.
이용 사례
구글 학술 검색에서 Deeplearning4j이 구현한 Word2vec을 인용한 결과를 볼 수 있습니다.
벨기에의 데이터 사이언티스트 Kenny Helsens는 Deeplearning4j의 Word2vec 구현을 NCBI’의 Online Mendelian Inheritance In Man (OMIM) 데이터베이스에 적용했습니다. 그리고 나서 그는 non-small cell lung carcinoma의 알려진 종양 유전자인 alk와 가장 유사한 단어가 무엇인지 검색했는데 그 결과는다음과 같습니다: “nonsmall, carcinomas, carcinoma, mapdkd.” 이를 이용해 Kenny는 다른 암 표현형들과 그들의 유전자형들 간의 유사성을 설립했습니다. 이는 데이터를 적절히 활용한 아주 좋은 예제 입니다. 질병 뿐만 아니라 온갖 분야에서 Word2vec을 적용할 수 있습니다.
스웨덴의 Andreas Klintberg는 DL4J의 Word2vec 구현 방법을 Medium에 자세히 정리해 놓았습니다.
Word2Vec는 DL4J가 딥 오토인코더를 사용해 질의응답 시스템을 구현하는 과정에서 아주 중요한 전처리기로 사용됩니다.
마케터들은 추천 엔진을 구축할 때 제품간의 관계를 Word2vec 벡터를 이용해 계산할 수 있습니다. 투자자들은 각종 그룹과 사람들의 관계를 Word2vec으로 구할 있습니다.
구글의 Word2vec 특허
Word2vec는 Tomas Mikolov를 비롯한 구글의 연구자들이 출판한 논문 단어의 벡터 표현들을 계산하는 방법을 통해 소개되었습니다. 구글은 Apache 2.0 라이센스를 적용한 오픈 소스 버전의 Word2vec를 호스팅하고 있습니다. 2014년, Mikolov는 구글을 떠나 페이스북으로 이직했고, 2015년 5월, 구글은 출시되어 온 Apache 라이센스를 폐지하지 않는 조건의 Word2vec 특허를 등록했습니다.
외국어
지금까지 살펴본 모든 과정은 언어에 관계 없이 적용 가능합니다. 하지만 적절한 데이터셋을 만들기 위한 자연어 전처리는 언어에 따라 다르게 적용되어야 합니다. 이 부분은 외부 라이브러리를 참고하시기 바랍니다. 예를 들어 Stanford Natural Language Processing Group은 만다린 중국어, 아랍어, 프랑스어, 독일어 및 스페인어 등의 토큰화, 품사 태깅 및 고유명사 인식 등 다양한 기능을 갖고 있으며 Java로 구현되어 있습니다. 일본어는 Kuromoji가 유명합니다. 텍스트 말뭉치 등 다국어 리소스는 여기를 참고하시기 바랍니다.
GloVe: Global Vectors
GloVe는 아래의 코드를 참고하십시오.
WordVectors wordVectors = WordVectorSerializer.loadTxtVectors(new File("glove.6B.50d.txt"));
SequenceVectors
Deeplearning4j는 SequenceVectors라는 클래스를 갖고 있습니다. 이 클래스는 단어 벡터보다 한 단계 더 추상화 된 클래스로, 각종 시퀀스 데이터 - 소셜 미디어 프로필, 거래 내역, 단백질 등 -의 속성들을 추출합니다. 학습 과정은 skip-gram과 계층적 softmax (Hierarchic softmax)로 이루어져 있습니다. 이것은 DeepWalk 알고리즘과도 호환이 되며 이 DeepWalk 알고리즘도 DL4J에 구현이 되어있습니다.
Deeplearning4j에 구현된 Word2Vec의 속성
- 모델 직렬화/역 직렬화 후 계수(weights) 업데이트가 추가되었습니다. 간단히 설명하면
loadFullModel로 추가할 텍스트 데이터를 불러온 뒤TokenizerFactory및SentenceIterator를 추가하고 마지막에 모델에서fit()을 실행하면 추가된 데이터로 모델이 업데이트됩니다. - 여러 개의 데이터에서 단어를 생성하는 옵션이 추가되었습니다.
- Epochs와 Iterations 값을 변경할 수 있습니다. (그러나 “1”로 두는 경우가 일반적입니다.)
Word2Vec.Builder는hugeModelExpected옵션을 가지고 있습니다. 이 값을true로 설정하면 모델을 빌드하는 과정에서 주기적으로 단어를 잘라냅니다.minWordFrequency를 적절히 설정할 수 있습니다.- WordVectorsSerialiaztion 방식은 두 가지가 있습니다.
writeFullModel와loadFullModel입니다. - 최신 워크스테이션은 몇 백만개의 단어를 처리합니다. Deeplearning4j의 Word2vec 구현은 단일 머신에서 수 테라 바이트의 데이터를 모델링 할 수 있습니다. 데이터의 크기는 대략
vectorSize * 4 * 3 * vocab.size()으로 계산합니다.
학습 자료
- DL4J 단락 벡터로 텍스트를 분류
- DL4J의 Doc2vec(문서 벡터), 또는 단락 벡터
- 사고 벡터, 자연어 처리 & AI의 미래
- Quora: Word2vec의 작동 원리
- Quora: Word2Vec을 이용한 재미있는 결과물
- Word2Vec 소개; Folgert Karsdorp
- Mikolov’의 Word2vec 코드 원문 @구글
- word2vec 설명: Mikolov et al.’의 Negative-Sampling Word-Embedding 방식 도출하기; Yoav Goldberg와 Omer Levy
- Bag of Words & 용어 빈도-역 문서 빈도 (TF-IDF)
다른 초보자 가이드
- 심층 신경망 소개
- 초보자를 위한 RNNs과 LSTM 가이드
- 고유 벡터(Eigenvectors), PCA, 공분산(Covariance) 및 엔트로피(Entropy)에 대한 기초 강의
- 컨볼루션 네트워크
- 초보자용 RBM(Restricted Boltzmann Machines) 튜토리알
- Neural Networks & Regression
- 심층학습(딥러닝) 활용 사례
문학 속의 Word2Vec
수식은 마치 언어와 같다. 단어를 숫자로 번역하면 누구나 정확히 그 말을 이해할 수 있다. 목소리, 억양, 아, 어, 오 등 모든 발음이 사라지고 모든 오해가 해결되며 정확한 숫자로 생각을 포현한다. 모든 개념을 명확하게 표현하는 것이다. – E.L. Doctorow, Billy Bathgate