초보자용 RBM(Restricted Boltzmann Machines) 튜토리얼
내용
RBM의 정의와 구조
RBM(제한된 볼츠만 머신, Restricted Boltzmann machine)은 차원 감소, 분류, 선형 회귀 분석, 협업 필터링(collaborative filtering), 특징값 학습(feature learning) 및 주제 모델링(topic modelling)에 사용할 수 있는 알고리즘으로 Geoff Hinton이 제안한 모델입니다. (RBMs을 포함한 인공 신경망 이용 사례는 이용 사례 페이지를 참고하십시오).
RBM의 구조는 상대적으로 단순한 편입니다. RBM은 자체적으로도 사용할 수 있지만 다른 심층 신경망의 학습을 돕기 위해 쓰이기도 합니다. 이제부터 RBM의 작동 원리를 설명드리겠습니다.
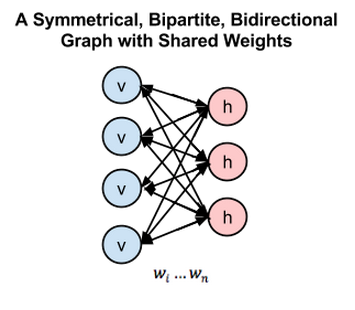
사실, RBM은 두 개의 층(입력층 1개, 은닉층 1개)으로 구성되어있기 때문에 심층 신경망이 아닙니다. 다만 RBM은 심층 신뢰 신경망(DBN:Deep Belief Network)을 구성하는 요소로 쓰입니다. 아래의 그림을 참고하시기 바랍니다. 첫번째 층은 우리가 볼 수 있는 층인 가시층(visible layer), 혹은 데이터가 입력되는 입력층이고 두번째 층은 특징값이 학습되는 은닉층입니다.
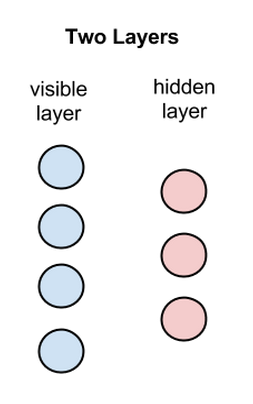
위 그림에서 원은 노드를 나타냅니다. 좌측의 파란 노드가 입력층의 노드이고, 우측의 붉은 노드가 은닉층의 노드에 해당하며 그림에는 연결이 생략되어 있지만 모든 은닉층의 노드는 입력층의 노드와 연결되어 있고, 모든 입력층의 노드도 은닉층의 노드와 연결되어 있습니다. 그러나 같은 레이어에 있는 노드끼리는 전혀 연결되어있지 않습니다.
다시말해, RBM에서는 같은 층 내부의 연결이 전혀 없으며, 이 구조때문에 ‘제한된’ 볼츠만 머신이라는 이름을 붙인 것입니다. 입력층의 노드는 데이터를 입력으며 입력받은 데이터를 은닉층에 얼마나 전달할 것인지를 확률에 따라 결정(stochastic decision)합니다. 즉 확률에 따라 입력을 전달할지(1) 혹은 전달하지 않을지(0)를 결정합니다.
각 입력 노드는 데이터의 저수준 특징값 혹은 속성을 받아옵니다. 예를 들어 흑백 이미지가 입력 데이터라면 각 입력 노드는 이미지의 픽셀 값에 해당합니다. 만일 MNIST 데이터 셋을 사용한다면 입력 노드의 개수는 데이터 셋의 이미지의 픽셀 수(784)와 같게 설정됩니다.
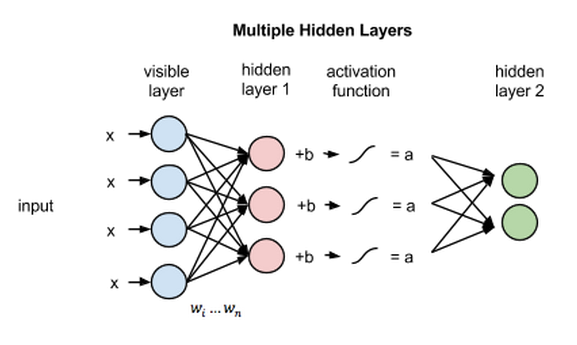
이제 위의 구조에 이미지를 넣었다고 가정하고 실제로 어떤 값이 어떻게 결정이 되는지 살펴보겠습니다. 아래 그림처럼 입력으로 x를 넣으면 그 은닉층의 노드에 있는 가중치 w와 곱해집니다. 그리고 바이어스(b)를 더한 값(w*x+b)을 활성함수 f()에 넣은 것이 노드의 출력이 됩니다.
activation f((weight w * input x) + bias b ) = output a
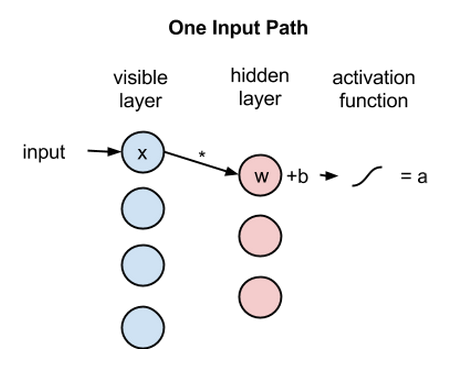
위의 식은 은닉 노드 하나에 들어오는 여러 개의 입력 중 하나만 고려한 식입니다. 아래 그림처럼 실제로는 여러 입력 노드의 값을 받아서 각자 다른 가중치 w와 곱해집니다. 그리고 그 총합에 바이어스를 더한 뒤 활성함수에 들어갑니다. 즉 f(x_1*w_1 + x_2*w_2 + x_3*w_3 + x_4*w_4 + b)가 은닉 노드의 출력입니다.
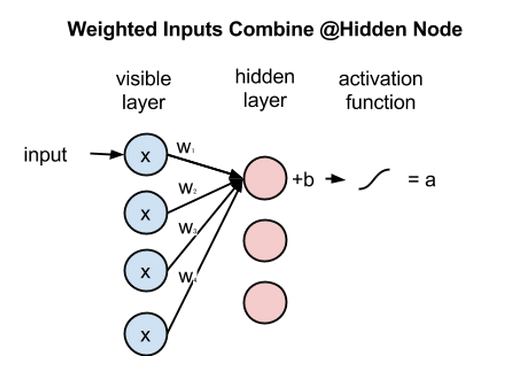
이렇게 모든 가시층의 노드가 모든 은닉 노드로 전달되는 것 특징 때문에 RBM은 대칭 이분 그래프(symmetrical bipartite graph)라고 부릅니다.
즉, ‘두’ 층이 ‘대칭’적으로 모두 연결되어 있어 있는 그래프입니다.
그림에는 생략되어있지만 4개의 입력 노드는 3개의 은닉 노드에 모두 연결되어있습니다. 그리고 각 연결마다 각자 다른 가중치 값이 있습니다. 따라서 총 12개(4*3)의 가중치가 있습니다. 이런 경우에 일반적으로 이 가중치를 4x3 행렬로 나타냅니다.
위에서 설명한 계산은 모든 은닉 노드에서 일어납니다. 즉 각 은닉 노드마다 4개의 입력 값에 적당한 가중치를 곱해 그 값을 더합니다. 그리고 거기에 바이어스를 더한 뒤 이를 활성 함수에 통과시킵니다.
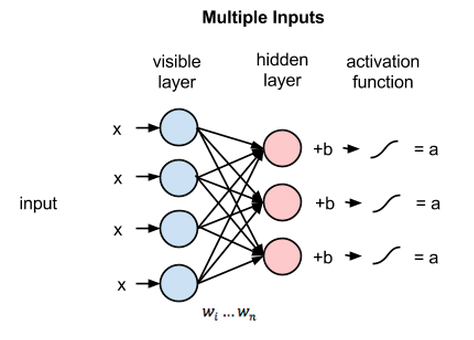
심층 신경망이라면 이렇게 계속 층을 쌓아서 전체 신경망 구조를 만듭니다. 그리고 최종적으로 출력층에서는 데이터를 분류한다든지 하는 작업을 수행합니다.
재구성
RBM의 목적은 조금 다릅니다. 여기에선 RBM을 이용한 비지도학습(unsupervised learning)을 소개하려고 합니다. 비지도학습은 데이터의 라벨을 학습하는 것이 아니라 입력 데이터만을 가지고 수행하는 작업을 의미합니다.
여기서 수행할 작업은 재구성(reconstruction)입니다. 데이터를 RBM에 입력하고 학습시키면 RBM이 데이터를 스스로 재구성할 수 있게 됩니다. 재구성 과정은 위에서 설명한 과정의 반대 방향으로 진행됩니다. 은닉층의 값을, 위와 같은 12개의 가중치를 이용해 입력 노드로 전달하고 입력 노드에서는 그 값을 다 더합니다. 그리고 거기에 바이어스를 더한 값이 은닉층을 이용해 재구성한 입력이 됩니다. 이 값은 입력값의 근사치입니다. 아래 그림을 참고하십시오.
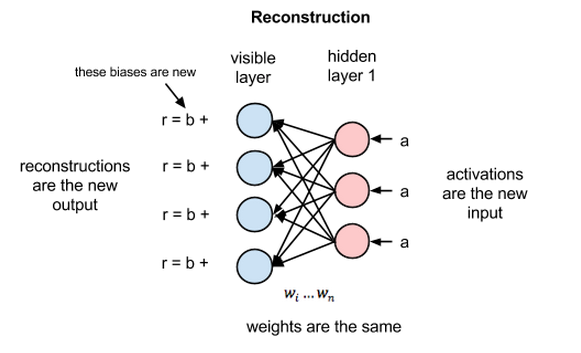
학습이 일어나기 전에는 가중치를 임의의 값으로 초기화합니다. 따라서 이렇게 재구성한 값은 실제 입력값과 많이 다를 수 있습니다. 위 그림에서 r, 즉 재구성한 값과 입력값의 차이는 오차가 됩니다. 이 오차는 (다른 인공 신경망 학습과정과 마찬가지로) backprop됩니다. 그리고 RBM의 학습은 위의 두 과정을 반복하면서 점점 오차를 줄여나갑니다.
Backprop은 여기에 자세히 설명되어있습니다.
입력 데이터로 은닉층의 값을 추정하는 과정은 w가 주어졌을 때 입력 x에 대한 은닉층 a의 조건부 확률 p(a|x; w)이 됩니다.
반대로 재구성 단계는 w가 주어졌을 때 은닉층 a에 대한 입력 x의 조건부 확률, 즉 p(x|a; w)를 추정하는 과정입니다.
결과적으로 두 추정치는 입력과 은닉층의 결합확률분포 p(x, a)의 추정입니다.
재구성은 회귀나 분류와 다릅니다.
재구성은 입력 데이터의 확률 분포를 추정하는 과정, 즉 생성 모델을 학습(generative learning)하는 과정으로 입력-출력의 관계를 찾는 분류 모델(discriminative learning)과 다릅니다.
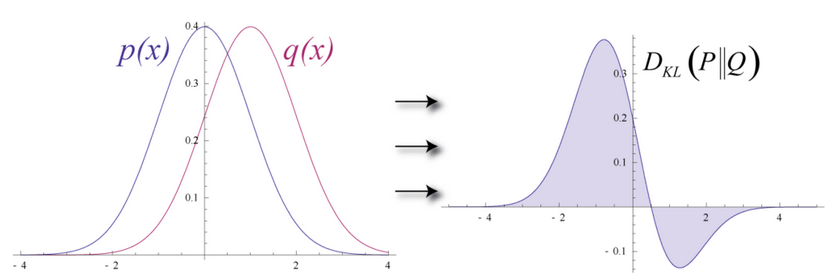
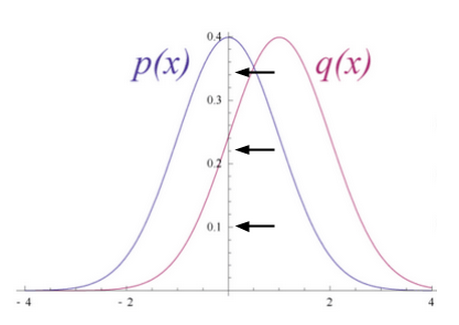
입력 데이터와 재구성한 추정치의 분포가 아래 그림의 p(x)와 q(x)처럼 겹치는 구간이 있지만 완벽하게 일치하지는 않는 경우라고 가정해봅시다.
RBM에서는 이렇게 두 분포가 얼마나 유사한지 측정하는 방법으로 KLD(Kullback Leibler Divergence, 쿨백-라이블러 발산)을 사용합니다.
아래 그림을 보면 두 확률 분포가 겹치지 않는 부분이 있습니다. 이를 발산(divergence)이라고 하는데 RBM의 최적화는 이 발산이 최소화되도록 하는 알고리즘입니다. 따라서 최적화는 두 분포를 유사하게 만들어주는 과정입니다.
이 최적화 과정은 가중치 w를 맞춰주는 과정입니다. 이렇게 가중치가 조절되면 가중치와 입력을 곱한 값인 은닉층의 값도 서서히 변해갑니다. 결과적으로 은닉층은 입력층을 나타내는 특징값(feature)이 되고, 학습이 잘 된 특징값과 가중치를 이용해 입력층을 근사하면 실제 입력과 유사한 확률 분포가 됩니다.
확률 분포
여기에선 확률 분포에 대해 다룹니다. 쉬운 예로 두 개의 주사위(검은색과 하얀색) 숫자의 합의 확률 분포는 아래 그림처럼 나타낼 수 있습니다.

그림을 보면 두 수의 합이 7이 될 확률이 가장 높습니다. 그리고 이 값을 추정하려면 7이 될 확률이 가장 높다는 사실을 참고해야 할 것입니다.
언어를 구성하는 글자는 각자 다른 확률 분포를 갖습니다. 예를 들어 영어에서는 e, t, a가 많이 나옵니다. 한편 아이슬란드어에서는 a, r, n이 가장 자주 나옵니다. 따라서 다른 언어를 모델링하려면 이런 분포를 고려해야합니다.
마찬가지로 이미지 데이터를 모델링하려면 각 픽셀의 값이 어떤 분포를 가지는지 알아야합니다. 아래 그림은 MNIST 데이터셋에 있는 이미지입니다. 우리가 다루는 이미지가 이렇게 손으로 쓴 숫자인지,
아래같은 아니면 “Labeled Faces in the Wild” 이미지처럼 사람의 얼굴인지에 따라 픽셀 값은 다른 확률 분포를 가집니다.

RBM에 코끼리 사진과 개 사진을 입력했다고 가정하겠습니다. 입력 값을 토대로 은닉층을 구하는 과정에서 RBM은 “이 입력 데이터를 보고, 코끼리를 나타내는 은닉 노드와 개를 나타내는 은닉 노드중에 어디에 더 강한 신호를 보내야 하는지”, 즉 가중치를 결정합니다. 그리고 재구성 단계에서는 “코끼리 은닉 노드의 값이 큰데, 이런 경우엔 픽셀의 분포가 어떤식인지”를 결정합니다.
이를 x가 주어졌을때 a의 분포인 조건부 확률과, 반대로 a가 주어졌을 때 a의 분포인 조건부 확률을 합친 결합 확률 분포(joint probability distribution)가 됩니다.
재구성을 학습하는 과정은 어떤 픽셀들이 동시에 큰 값을 지니는지 그 경향을 학습하는 과정입니다. 예를 들어 코끼리 사진이라면 코끼리의 모습 - 길고 구부러진 코, 큰 귀, 다리 - 등의 중요한 특징을 학습합니다.
위의 숫자와 얼굴 사진은 DL4J에서 구현한 RBM이 재구성한 이미지입니다. 이 재구성한 이미지를 통해 우리는 RBM이 숫자나 얼굴을 어떻게 “생각”하는지 알 수 있습니다. Geoff Hinton은 이것을 기계가 “꿈을 꾸는 것”이라고 표현했습니다. 이런 시각화로 우리는 RBM의 학습이 잘 이루어지는지 확인할 수 있습니다.
마지막으로, RBM은 입력층과 은닉층에 다른 바이어스를 갖고 있으며 이것이 다른 오토인코더와 RBM의 차이입니다.
심층 구조
이렇게 RBM의 은닉층의 학습이 끝나고 나면 이 데이터는 다시 다음 층으로 연결됩니다. 이 두번째 연결에서는 은닉층이 가시층의 역할을 하고, 새로운 추가한 층이 은닉층이 됩니다. 즉, 첫번째 연결에서 은닉층이 학습한 내용을 가지고 다시 새로운 RBM을 학습하는 것입니다.
이렇게 연달아 은닉층을 잇고 학습하는 것이 각자 다른 층위의 특징값(feature hierarchy)을 학습하는 과정입니다. 심층 신경망은 이런 구조로 더 추상적이고 복잡한 데이터를 이해합니다.
은닉층을 새로 추가할때마다 기존 층의 데이터를 근사할 수 있도록 가중치의 학습이 이뤄집니다. 이런 과정을 층별 탐욕 비지도 선행학습(layerwise, greedy unsupervised pre-training)이라고 합니다. 각 층마다 최대한 오차를 줄이는 방향으로 학습이 이루어지기 때문에 층별 탐욕 학습이고, 이 모든 과정이 라벨의 정보가 없이 입력 데이터만을 가지고 이루어지기 때문에 비지도 학습이니다. 그리고 이 학습한 결과를 다시 다른 학습에 쓸 수 있기 때문에 선행학습이라고 부릅니다.
이렇게 선행학습이 된 가중치는 데이터의 분포를 이미 알고있기 때문에 이 값으로 초기화한 심층 신뢰 신경망은 더 좋은 성능을 보여줍니다.
RBM의 광범위한 활용 사례중에서도 특히 이 선행학습이 아주 유용합니다. 선행학습은 가중치를 학습시킨다는 의미에서 역방향전파(backpropagation)와 유사한 역할을 합니다.
RBM의 전체 과정은 아래 그림처럼 나타낼 수 있습니다.
RBM은 구조적으로 directional, acyclic graph (DAG)에 속합니다. 자세한 설명은 링크를 참조하시기 바랍니다.
코드 샘플: DL4J로 Iris 상에서 RBM 초기화 하기
아래 코드는 NeuralNetConfiguration에서 RBM층을 만드는 과정입니다. 주석을 참고하면 가시층의 값을 가우시안으로 결정하는 과정을 볼 수 있습니다.
public class RBMIrisExample {
private static Logger log = LoggerFactory.getLogger(RBMIrisExample.class);
public static void main(String[] args) throws IOException {
// Customizing params
Nd4j.MAX_SLICES_TO_PRINT = -1;
Nd4j.MAX_ELEMENTS_PER_SLICE = -1;
Nd4j.ENFORCE_NUMERICAL_STABILITY = true;
final int numRows = 4;
final int numColumns = 1;
int outputNum = 10;
int numSamples = 150;
int batchSize = 150;
int iterations = 100;
int seed = 123;
int listenerFreq = iterations/2;
log.info("Load data....");
DataSetIterator iter = new IrisDataSetIterator(batchSize, numSamples);
// Loads data into generator and format consumable for NN
DataSet iris = iter.next();
iris.normalizeZeroMeanZeroUnitVariance();
log.info("Build model....");
NeuralNetConfiguration conf = new NeuralNetConfiguration.Builder().regularization(true)
.miniBatch(true)
// Gaussian for visible; Rectified for hidden
// Set contrastive divergence to 1
.layer(new RBM.Builder().l2(1e-1).l1(1e-3)
.nIn(numRows * numColumns) // Input nodes
.nOut(outputNum) // Output nodes
.activation("relu") // Activation function type
.weightInit(WeightInit.RELU) // Weight initialization
.lossFunction(LossFunctions.LossFunction.RECONSTRUCTION_CROSSENTROPY).k(3)
.hiddenUnit(HiddenUnit.RECTIFIED).visibleUnit(VisibleUnit.GAUSSIAN)
.updater(Updater.ADAGRAD).gradientNormalization(GradientNormalization.ClipL2PerLayer)
.build())
.seed(seed) // Locks in weight initialization for tuning
.iterations(iterations)
.learningRate(1e-3) // Backprop step size
// Speed of modifying learning rate
.optimizationAlgo(OptimizationAlgorithm.LBFGS)
// ^^ Calculates gradients
.build();
Layer model = LayerFactories.getFactory(conf.getLayer()).create(conf);
model.setListeners(new ScoreIterationListener(listenerFreq));
log.info("Evaluate weights....");
INDArray w = model.getParam(DefaultParamInitializer.WEIGHT_KEY);
log.info("Weights: " + w);
log.info("Scaling the dataset");
iris.scale();
log.info("Train model....");
for(int i = 0; i < 20; i++) {
log.info("Epoch "+i+":");
model.fit(iris.getFeatureMatrix());
}
}
// A single layer learns features unsupervised.
}
이 코드는 RBM processing the Iris flower dataset의 일부입니다. 자세한 설명은 해당 링크를 참고하시기 바랍니다.
파라미터터 & k
RBM 학습 변수 중 k는 contrastive divergence를 실행하는 횟수입니다. Contrastive divergence는 학습에서 사용하는 기울기(네트워크의 가중치와 오차의 그라디언트)를 구하는 알고리즘입니다.
k는 contrastive divergence의 실행 과정에서 사용하는 마르코프 체인의 값으로 보통 1로 설정합니다.
위의 예제 코드에서 RBM은 MultiLayerConfiguration 클래스로 생성되었습니다. 이제 각 매개변수에 대해 알아보겠습니다.
weightInit (weightInitialization)은 가중치를 어떤 값으로 초기화할지 보여줍니다. 가중치를 적당한 값으로 초기화하면 학습 속도가 빨라집니다.
activationFunction는 노드에서 사용할 활성 함수를 지정합니다.
optimizationAlgo는 신경망이 오차를 최소화하는데 사용하는 최적화 알고리즘을 의미합니다. 코드에서 사용한 LBFGS는 최적화 알고리즘의 이름입니다.
regularization은 과적응을 막기 위해 사용하는 규제 방법을 정합니다. 기계학습에서 과적응이 일어나는 경우에 가중치의 절대값이 커지는 경우가 많ㅇ습니다. 따라서 가중치의 크기와 관련한 값을 목적함수에 넣어서 이런 과적응을 막아줍니다.
VisibleUnit/HiddenUnit은 신경망의 층을 의미합니다. VisibleUnit은 입력층, HiddenUnit은 은닉층입니다.
lossFunction은 전체 오차를 측정하는 함수로 목적함수(objective function)라고도 부릅니다. 여기에서는 오차의 제곱을 최소화하는 SQUARED_ERROR를 사용합니다.
learningRate는 신경망의 학습률입니다. 학습률이 너무 작으면 학습 시간이 오래걸립니다. 반대로 학습률이 너무 크면 목적함수가 발산합니다.
연속 RBM
연속 RBM(CRBM, continuous RBM)은 입력 값으로 연속적인 값(정수가 아닌 값)을 사용할 수 있는 RBM입니다. CRBM도 일반적인 RBM처럼 constrastive divergence를 사용하지만 그 형식이 조금 다릅니다.CRBM을 쓰면 이미지 픽셀을 0에서 1 사이의 값으로 바꿔서 처리할 수 있습니다.
잠시 심층 신경망의 구성 요소를 다시 짚고 넘어가겠습니다. 심층신경망은 입력, 계수, 바이어스, 활성함수로 구성되어있습니다.
입력은 한 단계 앞에 있던 층에서 (혹은 입력 데이터에서) 받아오는 값입니다. 계수(coefficient)는 가중치(weights)라고도 하는데, 말 그대로 입력에 적용되는 가중치입니다. 바이어스는 입력의 가중치합에 더해지는 값으로 ‘y절편’과 비슷하며 노드의 값에 오프셋을 주어서 노드가 활성화되도록 돕습니다. 활성함수는 최종적으로 출력에 적용되는 값으로 연산에 비선형성(nonlinearity)을 더합니다.
이 네 가지 구성요소는 층마다 다르게 설정되기도 합니다.
연속값을 취하는 RBM은 가시층엔 가우시안 함수(Gaussian transformations)를, 은닉층엔 ReLU(rectified linear unit)를 활성함수로 씁니다. 특히 이 설정은 얼굴 이미지 재구성에서 좋은 결과를 보여주었습니다. 이진값(binary data)를 다루는 경우라면 두 층의 활성 함수도 두 종류의 값만 출력하게 됩니다.
은닉층에서는 가우시안 활성함수를 잘 쓰지 않습니다. 이진값을 가우시안 함수에 넣는 것보다 ReLU함수를 쓰는 경우가 더 좋은 결과를 보여줍니다. 심층 신뢰망도 이렇게 구성되어있습니다.
결론 및 다음 단계
학습 과정에서는 RBM의 출력 값을 얼마나 학습이 이루어졌나를 나타내는 지표로 사용할 수 있습니다. 재구성의 결과가 0이 아니라면 RBM이 잘 학습하고 있다는 의미입니다. RBM에 대한 더 자세한 이해는 이 문서를 참고하십시오.
이제 RBM을 이용한 심층 신뢰망(deep-belief network)을 구현하는 방법을 참고하시기 바랍니다.
학습 자료
- Geoff Hinton on Boltzmann Machines
- Deeplearning.net의 Restricted Boltzmann Machine 튜토리얼
- A Practical Guide to Training Restricted Boltzmann Machines; Geoff Hinton