Bag of Words & TF-IDF
Bag of Words (BoW) is an algorithm that counts how many times a word appears in a document. Those word counts allow us to compare documents and gauge their similarities for applications like search, document classification and topic modeling. BoW is a method for preparing text for input in a deep-learning net.
BoW lists words with their word counts per document. In the table where the words and documents effectively become vectors are stored, each row is a word, each column is a document and each cell is a word count. Each of the documents in the corpus is represented by columns of equal length. Those are wordcount vectors, an output stripped of context.
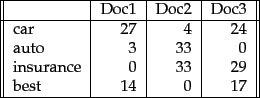
Before they’re fed to the neural net, each vector of wordcounts is normalized such that all elements of the vector add up to one. Thus, the frequencies of each word is effectively converted to represent the probabilities of those words’ occurrence in the document. Probabilities that surpass certain levels will activate nodes in the net and influence the document’s classification.
GET STARTED WITH MACHINE LEARNING
Term Frequency-Inverse Document Frequency (TF-IDF)
Term-frequency-inverse document frequency (TF-IDF) is another way to judge the topic of an article by the words it contains. With TF-IDF, words are given weight – TF-IDF measures relevance, not frequency. That is, wordcounts are replaced with TF-IDF scores across the whole dataset.
First, TF-IDF measures the number of times that words appear in a given document (that’s term frequency). But because words such as “and” or “the” appear frequently in all documents, those are systematically discounted. That’s the inverse-document frequency part. The more documents a word appears in, the less valuable that word is as a signal. That’s intended to leave only the frequent AND distinctive words as markers. Each word’s TF-IDF relevance is a normalized data format that also adds up to one.

Those marker words are then fed to the neural net as features in order to determine the topic covered by the document that contains them.
Setting up a BoW looks something like this:
public class BagOfWordsVectorizer extends BaseTextVectorizer {
public BagOfWordsVectorizer(){}
protected BagOfWordsVectorizer(VocabCache cache,
TokenizerFactory tokenizerFactory,
List<String> stopWords,
int minWordFrequency,
DocumentIterator docIter,
SentenceIterator sentenceIterator,
List<String> labels,
InvertedIndex index,
int batchSize,
double sample,
boolean stem,
boolean cleanup) {
super(cache, tokenizerFactory, stopWords, minWordFrequency, docIter, sentenceIterator,
labels,index,batchSize,sample,stem,cleanup);
}
While simple, TF-IDF is incredibly powerful, and contributes to such ubiquitous and useful tools as Google search.
BoW is different from Word2vec, which we’ll cover next. The main difference is that Word2vec produces one vector per word, whereas BoW produces one number (a wordcount). Word2vec is great for digging into documents and identifying content and subsets of content. Its vectors represent each word’s context, the ngrams of which it is a part. BoW is good for classifying documents as a whole.
More Machine Learning Tutorials
- Deep Reinforcement Learning
- Deep Convolutional Networks
- Recurrent Networks and LSTMs
- Multilayer Perceptron (MLPs) for Classification
- Generative Adversarial Networks (GANs)
- Symbolic Reasoning & Deep Learning
- Using Graph Data with Deep Learning
- AI vs. Machine Learning vs. Deep Learning
- Markov Chain Monte Carlo & Machine Learning
- MNIST for Beginners
- Restricted Boltzmann Machines
- Eigenvectors, PCA, Covariance and Entropy
- Glossary of Deep-Learning and Neural-Net Terms
- Word2vec and Natural-Language Processing
- Deeplearning4j Examples via Quickstart
- Neural Networks Demystified (A seven-video series)
- Inference: Machine Learning Model Server