Using Neural Networks With Regression
Broadly speaking, neural networks are used for the purpose of clustering through unsupervised learning, classification through supervised learning, or regression. That is, they help group unlabeled data, categorize labeled data or predict continuous values.
While classification typically uses a form of logistic regression in the net’s final layer to convert continuous data into dummy variables like 0 and 1 – e.g. given someone’s height, weight and age you might bucket them as a heart-disease candidate or not – true regression maps one set of continuous inputs to another set of continuous outputs.
GET STARTED WITH MACHINE LEARNING
For example, given the age and floor space of a house and its distance from a good school, you might predict how much the house would sell for: continuous to continuous. No dummy variables like one finds in classification, just mapping independent variables x to a continuous y.
Reasonable people can disagree about whether using neural networks for regression is overkill. The point of this post is just to explain how it can be done (it’s pretty easy).
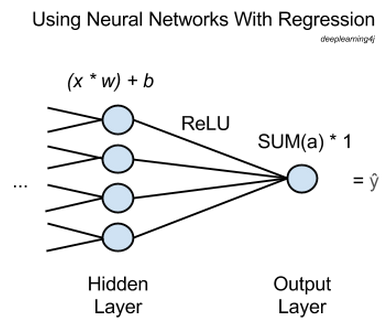
In the diagram above, x stands for input, the features passed forward from the network’s previous layer. Many x’s will be fed into each node of the last hidden layer, and each x will be multiplied by a corresponding weight, w.
The sum of those products is added to a bias and fed into an activation function. In this case the activation function is a rectified linear unit (ReLU), commonly used and highly useful because it doesn’t saturate on shallow gradients as sigmoid activation functions do.
For each hidden node, ReLU outputs an activation, a, and the activations are summed going into the output node, which simply passes the activations’ sum through.
That is, a neural network performing regression will have one output node, and that node will just multiply the sum of the previous layer’s activations by 1. The result will be ŷ, “y hat”, the network’s estimate, the dependent variable that all your x’s map to.
To perform backpropagation and make the network learn, you simply compare ŷ to the ground-truth value of y and adjust the weights and biases of the network until error is minimized, much as you would with a classifier. Root-means-squared-error (RMSE) could be the loss function.
In this way, you can use a neural network to get the function relating an arbitrary number of independent variables x to a dependent variable y that you’re trying to predict.
To perform regression with a neural network in Deeplearning4j, you would set up a multilayer neural network, and add an output layer at the end with the following properties:
//Create output layer
.layer()
.nIn($NumberOfInputFeatures)
.nOut(1)
.activationFunction('identity')
.lossFunction(LossFunctions.LossFunction.RMSE)
nOut is the number of nodes in any layer. nIn is the number of features being passed from the previous layer – in the diagram above it would be 4. activationFunction should be set to 'identity'.
Here’s a more complete example of using a neural network for regression in order to approximate simple mathematical functions.
Other Deep Learning Tutorials
- LSTMs and Recurrent Networks
- Introduction to Deep Neural Networks
- Convolutional Networks
- Eigenvectors, Covariance, PCA and Entropy
- Restricted Boltzmann Machines
- Deeplearning4j Quickstart Examples
- ND4J: A Tensor Library for the JVM
- MNIST for Beginners
- Glossary of Deep-Learning and Neural-Net Terms
- Generative Adversarial Networks (GANs)
- Word2vec and Natural-Language Processing
- Reinforcement Learning
- Graph Data and Deep Learning
- Symbolic Reasoning and Deep Learning