词袋与TF-IDF
词袋 (Bag of Words,简称BoW) 是一种统计某个词在一份文档中出现次数的算法。统计所得的词频数据可以用于比较文档并测量其相似性,具体应用包括搜索、文档分类、主题建模等。词袋法是为深度学习网络准备文本输入的方法。
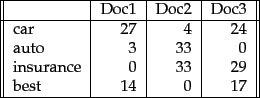
词袋法会列出每个词及其在每份文档中出现的次数。实质上已经向量化的词和文档被存储到表格中,表格的每一行对应一个词,每一列对应一份文档,而每个单元格则是一项词频数。语料库中的每份文档都以长度相等的列来表示。这也就是词频向量,一种脱离了上下文的输出。
在输入神经网络之前,每个词频向量都需要进行标准化,确保向量的所有元素之和为1。如此就相当于将每个词的频率转换为该词在文档中出现的概率。超过一定水平的概率会激活网络中的节点,对文档的分类产生影响。
词频-逆文档频率(TF-IDF)
词频-逆文档频率(TF-IDF)是另一种根据文章中包含的词来判断文章主题的方法。TF-IDF为词赋予权重——TF-IDF测量的是相关性,而非频率。因此,在整个数据集中,词频都会被TF-IDF分值所取代。
首先,TF-IDF会测量某一特定文档中的词的出现次数(即词频,term frequency)。但是,由于“and”、“the”之类的词所有文档中都频繁出现,这些词的频率需要调整。这就是逆文档频率的部分。出现某一个词的文档数量越多,这个词作为信号的价值就越小。这样做的目的是仅留下独特的高频词用作标记。每个词的TF-IDF相关性是一种标准化的数据格式,总和也是1。

随后,标记词会被当作特征输入神经网络,以确定包含这些词的文档的主题。
词袋的配置方式如下:
public class BagOfWordsVectorizer extends BaseTextVectorizer {
public BagOfWordsVectorizer(){}
protected BagOfWordsVectorizer(VocabCache cache,
TokenizerFactory tokenizerFactory,
List<String> stopWords,
int minWordFrequency,
DocumentIterator docIter,
SentenceIterator sentenceIterator,
List
<String> labels,
InvertedIndex index,
int batchSize,
double sample,
boolean stem,
boolean cleanup) {
super(cache, tokenizerFactory, stopWords, minWordFrequency, docIter, sentenceIterator,
labels,index,batchSize,sample,stem,cleanup);
}
TF-IDF虽然原理简单,但功能极其强大,在谷歌搜索等无处不在的实用工具中都有所应用。
词袋法与我们接下来要介绍的 Word2vec有所不同。主要的区别是:Word2vec为每个词生成一个向量,而词袋法则为每个词生成一个数字(词频)。Word2vec很适合对文档进行深入分析,识别文档的内容和内容子集。它的向量表示每个词的上下文,亦即词所在的n-gram。词袋法适合对文档进行总体分类。