Word2Vec
目录
- 简介
- 神经词向量
- 有趣的Word2vec结果
- 直接看代码
- Word2Vec解析
- 设置、加载、定型
- 代码示例
- Word2Vec疑难解答与调试
- Word2vec应用案例
- 外语
- GloVe(全局向量)与Doc2Vec
- 序列向量
- Deeplearning4j的Word2Vec特点
- Doc2vec和其他NLP资源
- 其他Deeplearning4j教程
- 文学中的Word2Vec
Word2Vec简介
Word2vec是一个用于处理文本的双层神经网络。它的输入是文本语料,输出则是一组向量:该语料中词语的特征向量。虽然Word2vec并不是深度神经网络,但它可以将文本转换为深度神经网络能够理解的数值形式。Deeplearning4j用Java和Scala语言实现分布式的Word2vec,通过Spark在GPU上运行。
Word2vec的应用不止于解析自然语句。它还可以用于基因组、代码、点赞、播放列表、社交媒体图像等其他语言或符号序列,同样能够有效识别其中存在的模式。
为什么呢?因为这些数据都是与词语相似的离散状态,而我们的目的只是求取这些状态之间的转移概率,即它们共同出现的可能性。所以gene2vec、like2vec和follower2vec都是可行的。而以下的教程就将介绍怎样为任何一组离散且同时出现的状态创建神经向量。
Word2vec的目的和功用是在向量空间内将词的向量按相似性进行分组。它能够识别出数学上的相似性。Word2vec能生成向量,以分布式的数值形式来表示词的上下文等特征。而这一过程无需人工干预。
给出足够的数据、用法和上下文,Word2vec就能根据过去经验对词的意义进行高度准确的预测。这样的预测结果可以用于建立一个词与其他词之间的联系(例如,“男人”和“男孩”的关系与“女人”和“女孩”的关系相同),或者可以将文档聚类并按主题分类。而这些聚类结果是搜索、情感分析和推荐算法的基础,广泛应用于科研、调查取证、电子商务、客户关系管理等领域。
Word2vec神经网络的输出是一个词汇表,其中每个词都有一个对应的向量,可以将这些向量输入深度学习网络,也可以只是通过查询这些向量来识别词之间的关系。
Word2vec衡量词的余弦相似性,无相似性表示为90度角,而相似度为1的完全相似则表示为0度角,即完全重合;例如,瑞典与瑞典完全相同,而挪威与瑞典的余弦距离为0.760124,高于其他任何国家。
以下是用Word2vec生成的“瑞典”的相关词列表:
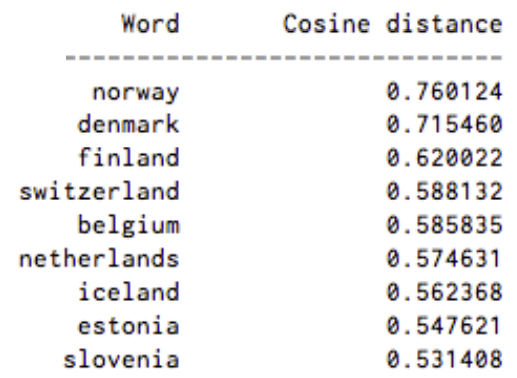
前九位中包括斯堪的纳维亚半岛国家和几个富裕的北欧及日耳曼语系国家。
神经词向量
我们用来表示词的向量称为神经词向量,这样的表示方式很奇特。虽然是两种完全不同的事物,但却能用其中一种来描述另一种事物。正如Elvis Costello所说:“写关于音乐的文字就像是跳关于建筑的舞蹈一样。”Word2vec将词“向量化”,从而使自然语言能被计算机读取-这样我们就可以对词语进行复杂的数学运算来识别词之间的相似性。
所以神经词向量用数字来表示词。这是一种简单而又不可思议的“翻译”。
Word2vec与自动编码器相似,它将每个词编码为向量,但Word2vec不会像受限玻尔兹曼机那样通过重构输入的词语来定型,而是根据输入语料中相邻的其他词来进行每个词的定型。
具体的方式有两种,一种是用上下文预测目标词(连续词袋法,简称CBOW),另一种则是用一个词来预测一段目标上下文,称为skip-gram方法。我们使用后一种方法,因为它处理大规模数据集的结果更为准确。
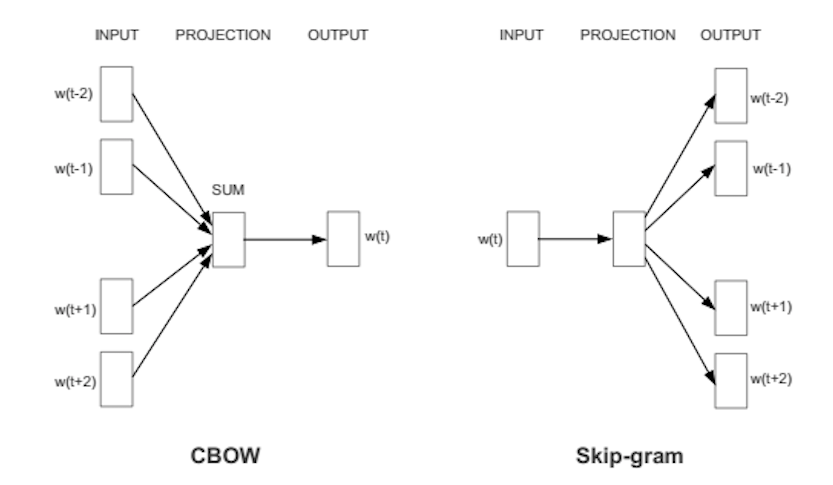
若指定给一个词的特征向量无法准确预测出这个词的上下文,则向量的要素会被调整。语料中每个词的上下文就是传回误差信号以调整特征向量的老师。若不同词的向量按上下文判定为相似,则会调整向量中的数字,使这些向量靠得更近。
正如梵高的画作《向日葵》是用油画颜料在画布上混合组成的二维图形来表示十九世纪八十年代末巴黎的三维植物实物一样,一个包含500个数字的向量也可以用来表示一个词或一组词。
这些数字指出了每个词在500维向量空间中的位置。人们很难想象超过三维的空间。(Geoff Hinton在教学生想象13维空间时,要他们先想象三维空间,然后对自己说:“十三、十三、十三。”:)
一组定型良好的词向量会让相似的词语在向量空间内彼此靠近。橡树、榆树、桦树这些词可能聚集在空间的一个角落,而战争、冲突、斗争则挤在另一个角落。
类似的事物与概念也会比较“靠近”。他们的相对意义被转译为可衡量的距离。质量变为数量,让算法得以运行。但相似性只是Word2vec可以学习的许多种关联的基础。举例而言,Word2vec还可以衡量一种语言的词语之间的关系,并且将这些词相互映射。
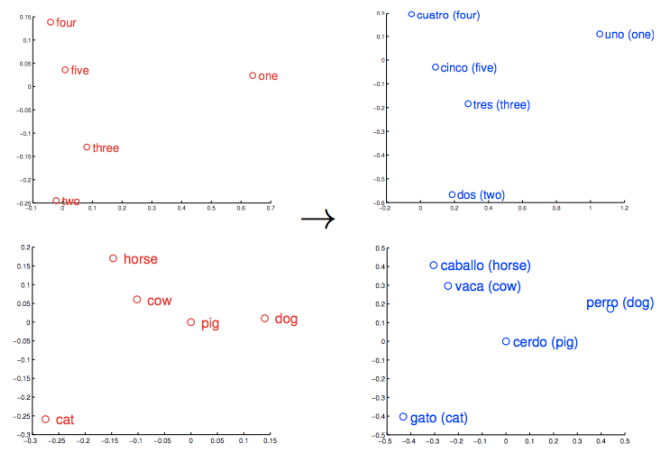
以这些向量为基础,可以得到更全面的词的几何分布。罗马、巴黎、柏林、北京这些首都的名称不仅会聚集在一处,彼此靠近,同时每个词在向量空间内到其对应国家名称的距离也是相似的;例如:罗马-意大利 = 北京-中国。如果你只知道意大利的首都是罗马,而不知道中国的首都在哪里,那么可以由计算式罗马-意大利 + 中国得出是北京。不骗你。
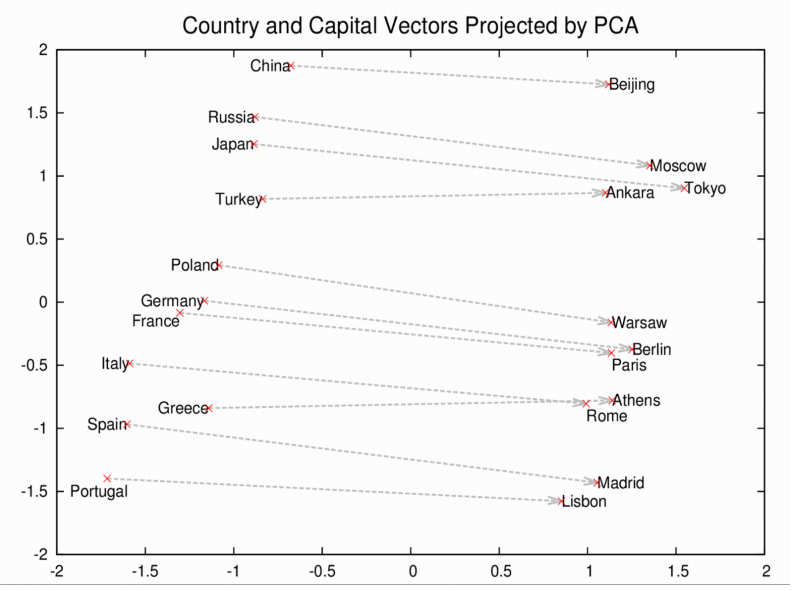
有趣的Word2Vec结果
让我们来看看Word2vec可以得出哪些其他的关联。
我们不用加号、减号和等号,而是用逻辑类比符号表示结果,其中 : 代 表“…与…的关系”,而 :: 代表“相当于”;比如“罗马与意大利的关系相当于北京与中国的关系” = Rome:Italy::Beijing:China。接下来我们不会直接提供“答案”,而是给出一个Word2vec模型在给定最初三个词后生成的词表:
king:queen::man:[woman, Attempted abduction, teenager, girl]
//有点奇怪,但能看出有些关联
China:Taiwan::Russia:[Ukraine, Moscow, Moldova, Armenia]
//两个大国和与之相邻且关系微妙的较小国家或地区
house:roof::castle:[dome, bell_tower, spire, crenellations, turrets]
knee:leg::elbow:[forearm, arm, ulna_bone]
New York Times:Sulzberger::Fox:[Murdoch, Chernin, Bancroft, Ailes]
//Sulzberger-Ochs家族是《纽约时报》所有人和管理者。
//Murdoch家族持有新闻集团,而福克斯新闻频道为新闻集团所有。
//Peter Chernin曾连续13年担任新闻集团的首席运营官。
//Roger Ailes是福克斯新闻频道的总裁。
//Bancroft家族将华尔街日报出售给新闻集团。
love:indifference::fear:[apathy, callousness, timidity, helplessness, inaction]
//这个组合真是饱含诗意……
Donald Trump:Republican::Barack Obama:[Democratic, GOP, Democrats, McCain]
//有趣的是,就像奥巴马和麦凯恩是竞争对手一样,
//Word2vec认为特朗普也与共和党人这个概念对立。
monkey:human::dinosaur:[fossil, fossilized, Ice_Age_mammals, fossilization]
//人类是变成化石的猴子?人类是
//猴子遗留下来的东西?人类是打败了猴子的物种,
//就像冰川世纪的哺乳动物打败了恐龙那样?好像有点道理。
building:architect::software:[programmer, SecurityCenter, WinPcap]
这个模型是用谷歌新闻词汇定型的,你也可以导入它来尝试一下。要知道,从未有人教过Word2vec算法任何一条英语句法规则。它对于世界一无所知,与一切符号逻辑和知识图并无关联。但它学到的内容要多于大多数知识图经过多年人工作业得到的学习成果,而且是以灵活自动的方式进行学习。它在开始接受谷歌新闻文档定型时只是白纸一张,而当定型结束后,Word2vec模型已能计算出人类多少能够理解的复杂类比。
你也可以用一个Word2vec模型查询其他关联。并非所有关联都必须是两组相似的类比。(后文有具体说明……)
- 地缘政治:伊拉克 - 暴力 = 约旦
- 特性:人类 - 动物 = 伦理
- 总统 - 权力 = 总理
- 图书馆 - 书 = 大厅
- 类比:股市 ≈ 温度计
通过确定一个词与其他相似的词之间的近似度(两个词不一定包含同样的字母),我们让硬性的标记变为更连续且更全面的意义。
神经词向量
解析DL4J中的Word2vec
以下是Deeplearning4j的自然语言处理组件:
- SentenceIterator/DocumentIterator:用于数据集的迭代。SentenceIterator返回字符串,而DocumentIterator则处理输入流。
- Tokenizer/TokenizerFactory:用于对文本进行分词。在NLP术语中,一个句子表示为一系列词例(token)。TokenizerFactory为一个”句子”创建一个分词器(tokenizer)实例。
- VocabCache:用于跟踪元数据,包括词频、含有某个词的文档的数量、词例的集合(不是词汇,而是已经出现过的词例),词汇(词袋以及词向量查找表中包含的特征)
- 倒排索引:存储有关词的出现位置的元数据。可用于理解数据集。会自动创建以Lucene实现[1]的索引。
Word2vec指一类彼此相关的算法,而以下是采用Skip-Gram负样本采样模型的实现方法。
Word2Vec设置
用Maven在IntelliJ中创建新项目。如果你不知道这一步如何操作,请查看快速入门页。随后在项目根目录下的POM.xml文件中指定以下属性和依赖关系(可以在Maven上查看最新版本-请使用那些版本…)。
加载数据
接下来在Java中创建并命名一个新的类。然后用迭代器遍历.txt文件中的原始语句,并且对这些句子进行某些预处理,例如把所有词转换为小写字母。
String filePath = new ClassPathResource("raw_sentences.txt").getFile().getAbsolutePath();
log.info("Load & Vectorize Sentences....");
// 删去每行前后的空格
SentenceIterator iter = new BasicLineIterator(filePath);
如果要加载本示例提供的句子以外的文本文件,你应该这样做:
log.info("Load data....");
SentenceIterator iter = new LineSentenceIterator(new File("/Users/cvn/Desktop/file.txt"));
iter.setPreProcessor(new SentencePreProcessor() {
@Override
public String preProcess(String sentence) {
return sentence.toLowerCase();
}
});
也就是要去除ClassPathResource,将你的.txt文件的绝对路径输入LineSentenceIterator。
SentenceIterator iter = new LineSentenceIterator(new File("/your/absolute/file/path/here.txt"));
在bash脚本中,进入任意一个目录内后在命令行中键入pwd即可得到该目录的绝对文件路径。然后在这个路径后面加上文件名就行了。
数据分词
Word2vec的输入应是词,而非整句句子,所以下一步需要对数据进行分词。文本分词就是将文本分解为最小的组成单位,比如每遇到一个空格就创建一个新的词例。
// 在每行中按空格分词
TokenizerFactory t = new DefaultTokenizerFactory();
t.setTokenPreProcessor(new CommonPreprocessor());
这样应该就能每行得到一个词。
模型定型
数据准备完毕后,就可以配置Word2vec神经网络并输入词例了。
log.info("Building model....");
Word2Vec vec = new Word2Vec.Builder()
.minWordFrequency(5)
.iterations(1)
.layerSize(100)
.seed(42)
.windowSize(5)
.iterate(iter)
.tokenizerFactory(t)
.build();
log.info("Fitting Word2Vec model....");
vec.fit();
这一配置接受多项超参数。有一些需要说明:
- batchSize是每次处理的词的数量。
- minWordFrequency是一个词在语料中必须出现的最少次数。本例中出现不到五次的词都不予学习。词语必须在多种上下文中出现,才能让模型学习到有用的特征。对于规模很大的语料库,理应提高出现次数的下限。
- useAdaGrad-AdaGrad为每个特征生成一个不同的梯度。在此处不需要考虑。
- layerSize指定词向量中的特征数量,与特征空间的维度数量相等。以500个特征值表示的词会成为一个500维空间中的点。
- iterations是网络在处理一批数据时允许更新系数的次数。迭代次数太少,网络可能来不及学习所有能学到的信息;迭代次数太多则会导致网络定型时间变长。
- learningRate是每一次更新系数并调整词在特征空间中的位置时的步幅。
- minLearningRate是学习速率的下限。学习速率会随着定型词数的减少而衰减。如果学习速率下降过多,网络学习将会缺乏效率。这会使系数不断变化。
- iterate告知网络当前定型的是哪一批数据集。
- tokenizer将当前一批的词输入网络。
- vec.fit()让已配置好的网络开始定型。
用Word2vec评估模型
下一步是评估特征向量的质量。
// 编写词向量
WordVectorSerializer.writeWordVectors(vec, "pathToWriteto.txt");
log.info("Closest Words:");
Collection<String> lst = vec.wordsNearest("day", 10);
System.out.println(lst);
UiServer server = UiServer.getInstance();
System.out.println("Started on port " + server.getPort());
//输出:[night, week, year, game, season, during, office, until, -]
vec.similarity("word1","word2")一行将返回你所输入的两个词之间的余弦相似性。相似性越接近1,表示网络认为两个词越相似(见前文瑞典-挪威的例子)。例如:
Collection<String> lst3 = vec.wordsNearest("man", 10);
System.out.println(lst3);
//输出:[director, company, program, former, university, family, group, such, general]
模型的图像化
我们依靠TSNE来降低词特征向量的维度,将词向量投影至二维或三维的空间。
log.info("Plot TSNE....");
BarnesHutTsne tsne = new BarnesHutTsne.Builder()
.setMaxIter(1000)
.stopLyingIteration(250)
.learningRate(500)
.useAdaGrad(false)
.theta(0.5)
.setMomentum(0.5)
.normalize(true)
.usePca(false)
.build();
vec.lookupTable().plotVocab(tsne);
保存、重载、使用模型
你应该要保存模型。Deeplearning4j中保存模型的一般方法是使用序列化工具(Java的序列化与Python的腌制过程相似,将一个对象转换为一个字节的序列)。
log.info("Save vectors....");
WordVectorSerializer.writeWord2VecModel(vec, "pathToSaveModel.txt");
以上代码将把向量存入一个名为pathToSaveModel.txt的文件,保存在Word2vec定型所在目录的根目录中。文件中的输出应当是每行一个词,词后面跟着一个表示词向量的数字序列。
要继续使用这些向量,只需按以下代码调用vec方法:
Collection<String> kingList = vec.wordsNearest(Arrays.asList("king", "woman"), Arrays.asList("queen"), 10);
Word2vec最经典的词语算式例子是“king - queen = man - woman”(国王 - 王后 = 男人 - 女人),可由此推出“king - queen + woman = man”(国王 - 王后 + 女人 = 男人)。
上述示例会输出距离king - queen + woman这一向量最近的10个词,其中应当包括 man。wordsNearest的第一个参数必须包括king和woman这两个“正的”词,它们都带有加号;第二个参数则包括queen这个“负的”词,带有减号(此处的正负不代表任何潜在的感情色彩);第三个参数是词表的长度,即你希望得到多少个最接近的词。记得在文件顶端添加:import java.util.Arrays;。
参数可任意组合,但只有查询在语料中出现频率足够高的词,才能返回有意义的结果。显然,返回相似的词(或文档)的能力是搜索以及推荐引擎的基础。
你可以这样将向量重新载入内存:
Word2Vec word2Vec = WordVectorSerializer.readWord2VecModel("pathToSaveModel.txt");
随后可以将Word2vec作为查找表:
WeightLookupTable weightLookupTable = word2Vec.lookupTable();
Iterator<INDArray> vectors = weightLookupTable.vectors();
INDArray wordVectorMatrix = word2Vec.getWordVectorMatrix("myword");
double[] wordVector = word2Vec.getWordVector("myword");
如果词不属于已知的词汇,Word2vec会返回一串零。
导入Word2vec模型
我们用来测试已定型网络准确度的谷歌新闻语料模型由S3托管。如果用户当前的硬件定型大规模语料需要很长时间,可以下载这个模型,跳过前期准备直接探索Word2vec。
如果你是使用C向量或Gensimm定型的,那么可以用下面这行代码导入模型。
File gModel = new File("/Developer/Vector Models/GoogleNews-vectors-negative300.bin.gz");
Word2Vec vec = WordVectorSerializer.readWord2VecModel(gModel);
记得为导入的包添加import java.io.File;。
较大的模型可能会遇到堆空间的问题。谷歌模型可能会占据多达10G的RAM,而JVM只能以256MB的RAM启动,所以必须调整你的堆空间。方法可以是使用一个bash_profile文件(参见疑难解答),或通过IntelliJ本身来解决:
//点击:
IntelliJ Preferences > Compiler > Command Line Options
//然后粘贴:
-Xms1024m
-Xmx10g
-XX:MaxPermSize=2g
N-gram和Skip-gram
词是逐个读入向量的,并且按特定的范围进行来回扫描。这些范围就是n-gram,而一个n-gram是某一特定语言序列中n个连续项目的序列;与unigram、bigram、trigram、4-gram和5-gram一样,n-gram就是第n个gram。Skip-gram也就是从n-gram中丢弃一些项目。
由Mikolov提出的skip-gram表示法经证明比连续词袋等其他模型更为准确,因为其生成的上下文更为通用。DL4J实现Word2vec时使用的也是skip-gram方法。
这一n-gram随后被输入一个神经网络,让网络学习一个特定词向量的重要性-此处重要性的定义是向量指示更广泛的意义(或标签)的作用大小。
实用示例
上文介绍了Word2Vec的基本设置方法,以下是一个具体示例,说明如何在DL4J的API中使用Word2vec:
你可以参照快速入门中的指示在IntelliJ中打开这一示例,点击运行,看它如何运作。如果你向Word2vec模型查询一个定型语料中没有的词,那么返回的结果会是零。
Word2Vec疑难解答与调试
问:我碰到许多这样的堆栈轨迹
java.lang.StackOverflowError: null
at java.lang.ref.Reference.<init>(Reference.java:254) ~[na:1.8.0_11]
at java.lang.ref.WeakReference.
<init>(WeakReference.java:69) ~[na:1.8.0_11]
at java.io.ObjectStreamClass$WeakClassKey.<init>(ObjectStreamClass.java:2306) [na:1.8.0_11]
at java.io.ObjectStreamClass.lookup(ObjectStreamClass.java:322) ~[na:1.8.0_11]
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1134) ~[na:1.8.0_11]
at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1548) ~[na:1.8.0_11]
答:检查Word2vec应用的启动目录内部。这可能是一个IntelliJ项目的主目录,或者你在命令行中键入了Java的那个目录。其中应当有这样一些目录:
ehcache_auto_created2810726831714447871diskstore
ehcache_auto_created4727787669919058795diskstore
ehcache_auto_created3883187579728988119diskstore
ehcache_auto_created9101229611634051478diskstore
你可以关闭Word2vec应用并尝试删除这些目录。
问:我的原始文本数据中有一些词没有在Word2vec的对象内出现……
答:尝试对你的Word2vec对象使用.layerSize()来扩大层的规模,如下所示
JAVACopyWord2Vec vec = new Word2Vec.Builder().layerSize(300).windowSize(5)
.layerSize(300).iterate(iter).tokenizerFactory(t).build();
问:如何加载我的数据?为什么定型要花这么久?
答:如果你的句子全部是整句加载的,那么Word2vec的定型就可能需要很长时间。原因在于Word2vec是一个句子层面的算法,所以句子的边界非常重要,因为同现关系的统计数据是逐句收集的。(对于GloVe,句子的边界无关紧要,因为GloVe关注的是整个语料库中的同现关系。)许多语料的平均句子长度是六个词。如果窗口大小为5,则会进行30(此处为随机数)轮的skip-gram运算。如果你忘记指定句子的边界,就有可能会加载有10000个词长的“句子”。在这种情况下,Word2vec会尝试对长达10000个词的“句子”进行完整的skip-gram循环。DL4J在实现过程中假定一行就是一个句子。你需要插入自己的SentenceIterator和Tokenizer。DL4J不绑定任何语言,它会让你自行指定如何判断句子结束。方法之一是使用UimaSentenceIterator。它用OpenNLP来检测句子的边界。
问:为什么将整篇文档作为一个“句子”输入时,网络表现会与将文档切分为句子后输入有这么大的差别?
答:如果每个句子平均含有6个单词,而窗口大小为5,虽然理论上skip-gram最多可达10轮,但实际上没有一个词能进行这么多轮skip-gram。由于长度有限,句子无法容下完整的词窗口。对这样的句子而言,每个词最多可进行大约5轮skip-gram。
但如果您的“句子”有100万个词,那么除了开头的5个词和结尾的5个词以外,句子中的每个词都可进行10轮skip-gram。因此,构建模型的时间必然大大增加,而同现关系的统计数据也会因为句子边界缺失而发生变化。
问:Word2Vec如何使用内存?
答:Word2Vec的内存消耗大户是权重矩阵。计算方法很简单:词的数量 x 维度数量 x 2 x 数据类型的内存占用。
所以,如果您的Word2Vec模型有10万个词,数据类型为float,维度数量为100,那么矩阵的内存占用为100k x 100 x 2 x 4 (float类型大小) = 80MB RAM,还要加上字符串、变量、线程等占用的内存。
如果您加载一个预建的模型,它在构建时所占用的RAM大约小两倍,也就是40MB RAM。
目前最受欢迎的常用模型是谷歌新闻模型。该模型有3M的词,向量大小为300。这样的话,仅加载模型就需要3.6GB。另外还要加上3M的字符串,而字符串在Java中没有恒定的大小。所以,加载模型所需的内存通常为4~6GB左右,具体取决于JVM版本/供应商、垃圾回收状态、月相……
问:我完全按照你们的方法操作,但结果看起来还是不对。
答:首先要确保这不是标准化(Normalization)问题。一些任务,比如wordsNearest(),就是默认使用使用标准化权重(Normalized Weights),而其他的就是用非标准化权重。必须注意这个差异。
应用案例
谷歌学术记录了所有引用通过Deeplearning4j实现的Word2vec的论文。
比利时的数据科学家Kenny Helsens将通过Deeplearning4j实现的Word2vec应用于NCBI的在线人类孟德尔遗传(OMIM)数据库。随后他查询了与一种已知的非小细胞肺癌肿瘤基因“alk”最相似的词,Word2vec返回的结果是:“nonsmall、carcinomas、carcinoma、mapdkd”。在此基础上,他确定了其他癌症的表现型与基因型之间的类比关系。这只是Word2vec可以从大规模语料库中学到的关联的例子之一。对重要疾病做出新发现的潜力才刚开始显现,而在医学之外的领域也同样存在各种各样的机会。
Andreas Klintberg对Deeplearning4j实现的Word2vec进行了瑞典语的定型,并且在Medium上记录了完整的过程。
Word2vec特别适合为信息检索和QA系统预加工基于文本的数据,DL4J用深度自动编码器实现这一功能。
市场营销人员可能会通过确定产品之间的关系来打造推荐引擎。调查人员可能会依靠分析社交图谱来寻找某一个群体的成员,或者确定这些人与特定地点或资助者之间的其他关系。
谷歌的Word2vec专利
Word2vec是由Tomas Mikolov领导的一支谷歌研究团队提出的一种对词的向量表示进行运算的方法。谷歌提供一个开源的Word2vec版本 ,以Apache 2.0许可证发布。Mikolov于2014年离开谷歌,加入Facebook,而谷歌在2015年5月获得了Word2vec方法的专利,该专利并不撤销Word2vec发布时所使用的Apache许可证。
外语
虽然所有语言的词都可以通过Word2vec转换为向量,而Deeplearning4j也都能学习这些向量,但是不同语言的NLP预处理可能有很大差异,而且需要使用我们的学习库以外的工具。斯坦福自然语言处理组拥有一系列基于Java的分词、词性标注及命名实体识别工具,适用于汉语普通话、阿拉伯语、法语、德语和西班牙语等语言。对日语而言,Kuromoji一类的NLP工具很有用。其他外语相关的资源,包括文本语料,可以在此处找到。
GloVe:全局向量
可以通过以下方式将GloVe模型加载或保存至Word2vec.
WordVectors wordVectors = WordVectorSerializer.loadTxtVectors(new File("glove.6B.50d.txt"));
序列向量
Deeplearning4j有一个叫做SequenceVectors的类,它是向量上一级的抽象类,让你可以从包括社交媒体档案、交易信息、蛋白质信息等任何序列中提取特征。如果数据能称为序列,就可以用AbstractVectors通过skip-gram和层次softmax来学习。这与DeepWalk算法兼容,同样也在Deeplearning4j中实现。
Deeplearning4j的Word2Vec特点
- 添加了模型序列化/反序列化后的权重更新。也就是说,你可以通过调用
loadFullModel来用例如200GB的新文本更新模型状态,加上TokenizerFactory和SentenceIterator,并且对还原的模型调用fit()。 - 添加了词汇建设的多个数据来源选项。
- Epoch和迭代可以分别指定,尽管它们通常都是”1”。
- Word2Vec.Builder有这一选项:
hugeModelExpected。如果设定为真,词汇表在构建过程中会被周期性截断。 minWordFrequency可用于忽略语料库中很少见的词,但也可以按需要剔除任意数量的词。- 引入了两种新的
WordVectorsSerialiaztion方法:writeFullModel和loadFullModel,用于保存和加载完整的模型状态。 - 一台不错的工作站应当能够处理几百万词的词汇表。Deeplearning4j实现的Word2vec可以在一台计算机上进行数TB数据的建模。数学公式大致是:
vectorSize * 4 * 3 * vocab.size()。
Doc2vec和其他NLP资源
- 使用Word2vec和RNN的DL4J文本分类示例
- 使用段落向量的DL4J文本分类示例
- 用Deeplearning4j实现的Doc2vec,或称段落向量
- 思维向量、自然语言处理与人工智能的未来
- Quora:Word2vec的工作原理是什么?
- Quora:有哪些有趣的Word2vec结果?
- Word2Vec简介;Folgert Karsdorp
- Mikolov的Word2vec原始代码@Google
- word2vec解析:推导Mikolov等人的负样本取样词向量法;Yoav Goldberg和Omer Levy
- 词袋与词频-逆文档频率(TF-IDF)
其他Deeplearning4j教程
文学中的Word2Vec
好像数字就是语言,好像这语言里所有的字母都变成了数字,在每个人看来都是同一种意思。字母的声音都没了,不论它原来是个要咂嘴、喷气还是擦着上颚发的音,不论是“呜”还是“啊”,凡是可能让人误解的东西、凡是用声音或者意象来欺骗你的东西都没了,连口音也没了,而你得到了一种全新的理解力,一种数字的语言,所有事情在每个人看来都变得如同白纸黑字一般清楚。所以我说有一段时间就是在阅读数字。
—— E.L.Doctorow著《Billy Bathgate》