基于Spark的Deeplearning4j
深度学习的计算强度较高,所以对于规模非常大的数据集而言,速度很重要。您可以采用速度更快的硬件、优化的代码以及某种形式的并行来处理问题。
数据并行指切分大规模的数据集,然后将分片交给不同的神经网络,而每个网络可能都在各自不同的处理器核上运行。Deeplearning4j依靠Spark来实现数据并行,以并行方式训练模型,对这些模型产生的参数进行迭代式平均化,得到一个中央模型。(如Jeff Dean等人在这篇论文中所述,模型并行可以让多个模型分别负责大型数据集中的不同部分而无需平均化。)
请注意,如果您希望采用基于参数服务器的方法(需要更多设置步骤!),请参阅我们最新的分布式训练页
目录
- 概述
- 先决条件
- 基于Spark的DL4J如何进行分布式的网络训练
- 最简示例
- 配置TrainingMaster
- 在Spark上训练所需的依赖项
- Spark示例库
- 用GPU进行基于Spark的训练
- 在YARN上为Spark配置内存
- 用Spark本地性配置来改善训练表现
- 性能调试和训练表现信息收集
- 缓存/持久化RDD和RDD
- Kryo序列化与Deeplearning4j并用
- 在亚马逊Elastic MapReduce上使用英特尔MKL和Deeplearning4j
先决条件
本页假设读者已掌握Spark的基本工作方法。如果您还不熟悉如何设置Spark集群或运行Spark任务,本页不包含这方面的教程,请考虑先了解Spark的基础知识。Spark快速入门指南是学习如何运行Spark任务的理想材料。
如果您只是想寻找在同个服务器上运行多个模型的方法,请考虑改用ParallelWrapper。
ParallelWrapper采用为单个服务器优化的方式来实施相同的分布式训练思路(参数平均化与梯度共享)。
如果您有一台大型主机(64核或更多)或多个GPU,那么就应该使用ParallelWrapper。
请注意,Spark可以让您同时使用多个GPU和cuDNN,但在实际操作中,最难的是集群设置。DL4J本身仅是一项Spark任务,在此之外的领域不属于 我们的责任范畴。
如果您从未运行过基于JVM的Spark任务,我们建议用Maven的shade插件来构建一个Uber JAR。
本页余下内容将介绍运行Spark任务的具体细节,包括如何定制Spark任务以及如何将Spark接口用于DL4J。
如果您希望使用托管的Spark集群,请与我们联系
另一种运行和管理Spark集群的方法是利用弹性MapReduce等各类云端服务。
概述
Deeplearning4j支持在Spark集群上训练神经网络,以便加快网络训练速度。
DL4J定义了两个与MultiLayerNetwork和ComputationGraph相似的类,用于在Spark上训练神经网络:
- SparkDl4jMultiLayer,MultiLayerNetwork的包装类
- SparkComputationGraph,ComputationGraph的包装类
此二者均是标准单机类的包装类,所以不论是标准训练还是分布式训练,网络配置的过程(即创建一个MultiLayerConfiguration或ComputationGraphConfiguration)都是完全相同的。但是,基于Spark的分布式训练与本地训练有两个区别:数据的加载方式和训练的设置方式(需要一些额外的集群专用配置)。
在Spark集群上(使用spark-submit)进行网络训练的典型工作流程如下所示。
- 创建网络训练类。这通常需要用到下列代码:
- 指定网络配置(MultiLayerConfiguration或ComputationGraphConfiguration),与单机训练一样
- 创建一个TrainingMaster实例,指定分布式训练的实际开展方式(下文详述)
- 用网络配置和TrainingMaster对象创建SparkDl4jMultiLayer或SparkComputationGraph实例
- 加载训练数据。有几种不同的数据加载方式,各有利弊;详情将在后续的文档中提供
- 对SparkDl4jMultiLayer或SparkComputationGraph实例调用适当的fit方法
- 保存或使用已训练的网络(已训练的MultiLayerNetwork或ComputationGraph实例)
- 打包jar文件,准备用Spark submit提交
- 如果您在使用maven,方法之一是运行“mvn package -DskipTests”
- 以适合您的集群的启动配置调用Spark submit
注:对于单机训练,Spark本地可以和DL4J一同使用,不过我们不推荐这种方式(因为Spark的同步和序列化开销)。您可以考虑以下的方法:
- 单CPU/GPU系统可用标准的MultiLayerNetwork或ComputationGraph来训练
- 多CPU/GPU系统可采用ParallelWrapper。上述方法在功能上与运行Spark的本地模式相同,但开销更低(因而可以产生更好的训练表现)。
基于Spark的DL4J如何进行分布式的网络训练
DL4J的当前版本用一种参数平均化的流程来训练网络。未来版本可能会加入其他的分布式网络训练方法。
从概念上看,采用参数平均化方法的网络训练流程很简单:
- 主节点(Spark驱动)以初始的网络配置及参数开始运行
- 数据按TrainingMaster的配置被切分为一定数量的子集。
- 对数据分片进行迭代。对于每个分片的训练数据:
- 将配置、参数(以及动量/rmsprop/adagrad更新器状态,如适用)从主节点分发至各个工作器
- 每个工作器用数据分片中相应的一部分来训练
- 将参数(以及更新器状态,如适用)平均化,并将平均化结果返回至主节点
- 训练完毕,主节点得到已训练网络的一份副本
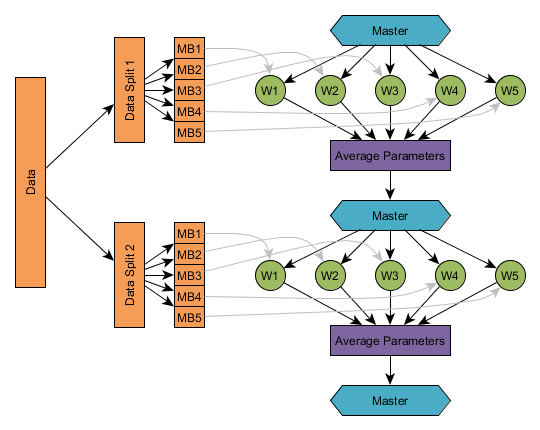
举例而言,下图显示了有五个工作器(W1、……、W5)的参数平均化流程,参数平均化频率为1。 和线下训练一样,训练数据集被切分为多个子集(在非分布式学习中一般称为微批次);先后用各个数据分片进行训练,每个工作器分到数据分片的一个子集。在实际操作中,分片的数量会依据训练配置(取决于工作器数量、平均化频率和工作器的微批次大小-参见配置段落)自动决定。
最简示例
本段介绍在Spark上训练网络所需的最基本要素。 有关各种数据加载方法的详情即将推出。
JavaSparkContent sc = ...;
JavaRDD<DataSet> trainingData = ...;
MultiLayerConfiguration networkConfig = ...;
//创建TrainingMaster实例
int examplesPerDataSetObject = 1;
TrainingMaster trainingMaster = new ParameterAveragingTrainingMaster.Builder(examplesPerDataSetObject)
.(other configuration options)
.build();
//创建SparkDl4jMultiLayer实例
SparkDl4jMultiLayer sparkNetwork = new SparkDl4jMultiLayer(sc, networkConfig, trainingMaster);
//用训练数据训练网络:
sparkNetwork.fit(trainingData);
配置TrainingMaster
DL4J中的TrainingMaster抽象类(接口)可以提供不同的训练实现,与SparkDl4jMultiLayer和SparkComputationGraph配合使用。
目前DL4J提供一种实现:ParameterAveragingTrainingMaster。它用于实现上文图中所示的参数平均化流程, 可以用构建器(builder)模式来创建:
TrainingMaster tm = new ParameterAveragingTrainingMaster.Builder(int dataSetObjectSize)
...(此处插入配置)
.build();
ParameterAveragingTrainingMaster定义了一系列配置选项,用于控制训练的执行方式:
- dataSetObjectSize:必需选项。在builder构造函数中指定。该项的值指定每个DataSet对象中有多少个样例。总体上的规则是:
- 如果训练使用的是经过预处理的DataSet对象, 该项的值应等于已预处理的DataSets对象的大小
- 如果训练直接使用字符串(例如CSV数据通过一些步骤转换为一个
RDD<DataSet>),那么该项的值通常为1
- batchSizePerWorker:该项目控制每个工作器的微批次大小。这与单机训练中的微批次大小设定相仿。换言之,这是每个工作器中每次参数更新所使用的样例数量。
- averagingFrequency:该项目控制参数平均化和再分发的频率,按大小等于batchSizePerWorker的微批次的数量计算。总体上的规则是:
- 平均化周期太短(例如averagingFrequency=1)可能效率不佳(相对于计算量而言,网络通讯和初始化开销太多)
- 平均化周期太长(例如averagingFrequency=200)可能会导致表现不佳(不同工作器实例的参数可能出现很大差异)
- 通常将平均化周期设在5~10个微批次的范围内比较保险。
- workerPrefetchNumBatches:Spark工作器能够以异步方式预抓取一定数量的微批次(DataSet对象),从而避免数据加载时的等待。
- 将该项的值设置为0会禁用预提取。
- 比较合理的默认值通常是2。过高的值在许多情况下并无帮助(但会使用更多的内存)
- saveUpdater:在DL4J中,动量、RMSProp和AdaGrad等训练方法称为“更新器”。大多数更新器都有内部历史记录或状态。
- 如果saveUpdater设为真:更新器的状态(在每个工作器中)将会被平均化并和参数一起返回至主节点;当前的更新器状态也会从主节点分发至工作器。这会增加额外的时间和网络流量,但有可能改善训练结果。
- 如果saveUpdater设为假:更新器状态(在每个工作器中)会被放弃,然后各个工作器中的更新器会被重置/重新初始化。
- rddTrainingApproach:从0.6.0版开始,DL4J提供两种用
RDD<DataSet>或RDD<MultiDataSet>训练的方法,分别是RDDTrainingApproach.Export(导出式)和RDDTrainingApproach.Direct(直接式)- 导出式:(默认)先将
RDD<DataSet>以分批次和序列化的形式保存至磁盘。执行器随后会按要求异步加载DataSet对象。这种方法的效果好于直接式方法,尤其是对大型数据集和多个epoch而言。如此可以避免直接式方法的切分和重分区开销,使用的内存也更少。临时文件可以用TrainingMaster.deleteTempFiles()来删除 - 直接式:这是DL4J早先版本的运作方法。对于内存可以完全容纳的小型数据集,这种方法可以带来较好的表现。
- 导出式:(默认)先将
- exportDirectory:仅用于导出式方法(上一种方法)。该项目控制临时数据文件的存储位置。默认:使用
{hadoop.tmp.dir}/dl4j/目录,其中{hadoop.tmp.dir}是Hadoop临时目录属性值。 - storageLevel:仅适用于(a)直接式训练方法,以及(b)用
RDD<DataSet>或RDD<MultiDataSet>数据训练时。这是DL4J持久化RDD的存储级别。默认:StorageLevel.MEMORY_ONLY_SER. - storageLevelStreams:仅在采用
fitPaths(RDD<String>)方法时适用。这是DL4J在持久化RDD<String>时所用的存储级别。默认:StorageLevel.MEMORY_ONLY。该默认值几乎适用于所有的情形。 - repartition:决定数据应在何时重分区的配置设定。
ParameterAveragingTrainingMaster会进行mapParititons操作;因此分区数量(以及每个分区中的值)对于集群的妥善利用有着重大意义。但是,重分区不是一项无开销的操作,因为一部分数据必须在整个网络中进行复制。具体有以下几种选项:- Always:默认选项,亦即始终对数据进行重分区,确保分区数量正确。推荐采用该选项,尤其是使用
RDDTrainingApproach.Export(0.6.0版开始为默认)或fitPaths(RDD<String>)时 - Never:从不对数据进行重分区,无论分区如何失衡。
- NumPartitionsWorkersDiffers:只有在分区数量和工作器数量(处理器核总数)不同的时候才进行重分区。请注意,即使分区数量等于处理器核的总数,也无法保证每个分区内的DataSet对象数量正确:有些分区可能会比其他分区大很多或小很多。
- Always:默认选项,亦即始终对数据进行重分区,确保分区数量正确。推荐采用该选项,尤其是使用
- repartitionStrategy:重分区的策略
- Balanced:(默认)这是DL4J自定义的一项重分区策略。与SparkDefault选项相比,这种策略会尝试确保分区之间更加平衡(就对象数量而言)。但在实际操作中,执行平衡策略需要额外的计数操作;在某些情况下(特别是小型网络或每个微批次计算量较少的网络),其效益可能无法超过改善重分区所需的额外开销。推荐采用该选项,尤其是使用
RDDTrainingApproach.Export(0.5.1版开始为默认)或fitPaths(RDD<String>)时 - SparkDefault:这是Spark所用的标准重分区策略。这种策略基本上就是将初始RDD中的每个对象单独地随机映射至N个RDD中的一个。因此,分区的平衡性可能不是最理想;由此造成的问题对比较小的RDD而言可能尤其严重,比如用于已预处理的DataSet对象和高频率平均化的小型RDD(原因就是随机采样差异)。
- Balanced:(默认)这是DL4J自定义的一项重分区策略。与SparkDefault选项相比,这种策略会尝试确保分区之间更加平衡(就对象数量而言)。但在实际操作中,执行平衡策略需要额外的计数操作;在某些情况下(特别是小型网络或每个微批次计算量较少的网络),其效益可能无法超过改善重分区所需的额外开销。推荐采用该选项,尤其是使用
在Spark上训练所需的依赖项
若要在Spark上运行DL4J,您需要安装deeplearning4j-spark依赖项:
<dependency>
<groupId>org.deeplearning4j</groupId>
<artifactId>dl4j-spark_${scala.binary.version}</artifactId>
<version>${dl4j.version}</version>
</dependency>
请注意,${scala.binary.version}是一项Maven属性,取值为2.10或2.11,应当与您所使用的Spark版本相匹配。
Spark示例库
Deeplearning4j示例库 (旧的示例见此处)中包含一些Spark示例。
用GPU进行基于Spark的训练
用CUDA在Spark上运行Deeplearning4j时,需要注意与YARN等集群管理器有关的一些事项。
YARN与GPU
YARN是一种常用的集群资源管理/调度工具,主要面向Hadoop集群。您可以用GPU在Spark+YARN上运行Deeplearning4j,但(与内存和CPU资源不同)YARN无法直接将GPU作为一种资源来跟踪/处理。因此,您一般需要完成几项额外步骤,才能用GPU在YARN上运行DL4J。这会造成两方面的问题:
- 在异类硬件集群(即某些计算机有GPU,某些没有)上会出现问题,因为YARN在原生状态下无法只将任务分配给装有GPU的计算机
- YARN有可能将两项甚至更多需要利用GPU的任务分配给单台计算机/GPU
解决办法之一是利用节点标签(2.6及更新版本的YARN提供这一功能)。节点标签让您可以依据自己的标准来对计算机进行标记或分组-此处需要的标准为是否装有GPU。在YARN配置中启用节点标签后,就可以创建相应的标签,添加至集群中的计算机。随后您就可以通过指定节点标签来要求Spark任务仅使用包含GPU的计算机。
关于节点标签及其配置方式的资源参见以下链接:
- https://hadoop.apache.org/docs/r2.7.3/hadoop-yarn/hadoop-yarn-site/NodeLabel.html
- https://docs.hortonworks.com/HDPDocuments/HDP2/HDP-2.4.2/bk_yarn_resource_mgt/content/configuring_node_labels.html
- https://developer.ibm.com/hadoop/2017/03/10/yarn-node-labels/
在YARN上启动GPU任务:
- 确保YARN配置中已启用节点标签
- 为装有GPU的计算机创建标签(一个或多个标签)
- 为每一台需要用于训练的GPU计算机添加上一步创建的节点标签
- 将
--conf spark.yarn.executor.nodeLabelExpression=YOUR_NODE_LABEL添加至Spark提交的启动配置 - 与DL4J的单机训练一样,系统必须装有CUDA,用于执行任务的路径中须有NVCC
- 由于YARN不会划分GPU或限制GPU的使用,您应当确保YARN只会为每个GPU节点分配一项GPU任务。具体实现方法可以是在使用GPU的任务中提出足够的CPU和内存要求,不让执行器留下足以接受另一项类似任务的容量。否则,YARN就有可能会把多项GPU任务分配给同个执行器,而不顾该执行器是否有足够的GPU资源来满足所有任务的需求。
- 2.6.0或更新版本的Hadoop
- 支持Docker的操作系统(控制组和命名空间为必需,因此必须采用3.x或更新版本的Linux内核。某些操作系统,例如CentOS 6、RHEL 6及其更旧版本不予支持)
- 每个节点上都已完成Docker客户端的安装与配置
- 正确配置的Docker镜像,用于启动您的任务
- YARN任务在容器(container)内运行,每个容器有固定的内存量
- 分配给一个YARN容器的内存量包括堆内内存总量(即JVM内存大小)和用户请求的堆外内存(YARN称之为“额外内存开销(memory overhead)”)
- 如果一项任务所需的内存超出了可以分配给容器的总量,YARN有可能会“杀死”(kill)容器和其中运行的执行器。具体行为取决于YARN的配置。
- 程序超出容器内存限制通常是因为堆外内存;堆内(JVM)内存的上限会通过Spark submit设置成固定的启动参数。
spark.executor.memory: 这是标准的JVM内存分配,与单一JVM的Xmx设置相同。spark.yarn.executor.memoryOverhead: 这是分配给容器的“额外”内存量。这部分内存不是分配给JVM的,因此可以供利用堆外内存的代码使用(包括ND4J/JavaCPP)。- 用
spark.executor.memory指定执行器JVM内存量 - 用
spark.yarn.executor.memoryOverhead指定YARN容器的额外内存开销 - 用
org.bytedeco.javacpp.maxbytes系统属性告诉ND4J/JavaCPP可以使用的堆外内存量 - 4个执行器,每个有8个核
- YARN可分配给容器的内存上限:11GB
- JVM(执行器和驱动)内存:4GB
- ND4J/JavaCPP堆外内存(执行器和驱动):5GB
- 额外的堆外内存:1GB
- 不使用
sparkNet.setCollectTrainingStats(true)——这项功能是可选的(不是训练必需的功能),默认情况下是禁用的 - 将系统的时间来源设置为本地计算机时钟,而非NTP服务器(但是注意这有可能导致时间线信息变得很不准确)。
MEMORY_ONLY和MEMORY_AND_DISK持久化在使用堆外内存时可能出现问题,因为Spark无法很好地估计RDD中对象的大小。这可能会造成内存不足的问题。- 若要持久化
RDD<DataSet>或RDD<INDArray>以供重复使用,请采用MEMORY_ONLY_SER或MEMORY_AND_DISK_SER - 从Deeplearning4j 0.5.1版开始,在默认情况下,训练数据(
RDD<DataSet>)将首先被导出至磁盘(这会改善表现,尤其是对较大的训练集而言);不必用手动方式持久化/缓存训练数据RDD,也不建议这样操作。(这一行为可以用rddTrainingApproach配置选项来配置)。 - MEMORY_ONLY
- MEMORY_AND_DISK
- MEMORY_ONLY_SER
- MEMORY_AND_DISK_SER
- DISK_ONLY
请注意,您可以为每个节点添加多个标签。利用多个标签可以实现更精细(不过需要手动完成)的任务/节点调度控制,也是避免YARN过度分配GPU资源的潜在方法之一。
用GPU和Spark/YARN运行DL4J时还需要注意以下问题。
有三种方法可以避免调度造成的问题:
首先,如上文所述,采用多个标签来手动控制调度。
其次,将足够的资源(核、内存)分配给容器,确保每个节点上没有分配其他需要利用GPU的任务。
第三,可以利用容器(具体而言,即Docker容器执行器),通过devices控制组来声明容器内正在使用GPU-确保GPU不会被分配给多项任务。一种比较简单的方法是使用nvidia-docker containers来为您处理这项声明。
Docker容器执行器的系统要求:
Mesos与GPU
Apache Mesos是另一种集群资源管理工具。与YARN不同,Mesos内建NVIDIA GPU的支持机制(自1.0.0版起),不存在YARN的GPU过度分配问题。因此,在其他条件相同的前提下,在Mesos上运行DL4J + GPU要比在YARN上运行相同的任务更容易。
在YARN上为Spark配置内存
Apache Hadoop YARN是Hadoop集群常用的资源管理器(Apache Mesos是另一种选择)。 用Spark submit向一个集群提交一项任务的时候,必须指定几个配置选项,比如执行器数量、每个执行器的处理器核数量,以及每个执行器的内存。
为了让基于Spark的DL4J训练取得最理想的表现(同时避免超出内存限制),还需要进行一些额外的内存配置。本段将解释其必要性,并介绍实际的操作方法。
Deeplearning4j(以及ND4J)的内存管理方式
Deeplearning4j建立在数值计算库ND4J的基础之上。DL4J中的神经网络实现是用ND4J中的矩阵和向量化运算构建的。
ND4J的设计要素之一是利用了堆外内存管理。这意味着ND4J分配给INDArrays的内存不在JVM堆之内(与标准的Java对象不同),而是属于JVM之外的单独的内存池。这种内存管理是用JavaCPP来实现的。
堆外内存管理有一系列好处。 最主要的是,它让高性能的本机(C++)代码可以被高效地用于数值运算(使用OpenBLAS和英特尔MKL等BLAS库,以及C++库Libnd4j)。堆外内存管理对于用CUDA进行高效的GPU运算也是必需的。如果分配了JVM堆内的内存(与其他JVM BLAS实现相同),就必须首先将数据从JVM复制出来,进行运算,再将结果复制回去——这样会增加每次运算所需的内存和时间开销。相比之下,ND4J在数值运算过程中只需要使用指针传递,完全避免了数据复制的问题。
此处的重点在于,堆内(JVM)内存和堆外(ND4J/JavaCPP)内存是两个相互独立的内存池,大小可以分别设置;在默认情况下,JavaCPP允许的堆外内存分配大小等于Runtime.maxMemory()的设置(参见代码)——这一默认设置与JVM用于配置Java内存的’Xmx’内存设置大小相等。
如需手动控制JavaCPP所能分配的堆外内存上限,可以设置org.bytedeco.javacpp.maxbytes系统属性。对于在本地运行的单一JVM,我们会用-Dorg.bytedeco.javacpp.maxbytes=1073741824来将堆外内存分配限制在1GB以内。后面的段落将会介绍如何在YARN上为Spark进行这项配置。
YARN的内存管理方式
如上文所述,YARN是一种集群资源管理器。在向一个由YARN管理的集群提交一项计算任务(比如DL4J Spark网络训练)时,YARN会负责管理有限资源池(内存、CPU核)的分配,决定如何将资源分配给您的任务(以及所有其他任务)。有关YARN和资源分配的更多细节,请参阅这篇文章和这篇文章。
与我们的应用情形相关的要点如下:
有两项关键的配置选项可以控制YARN分配给容器的内存量。
在默认情况下,spark.yarn.executor.memoryOverhead设置等于执行器内存的10%,下限为384MB。 更多详情请参阅Apache Spark的YARN文档。
由于ND4J会使用大量堆外内存,在Spark上训练时通常有必要提高额外内存开销的设置。
在YARN上为基于Spark的Deeplearning4j训练配置内存
根据上一段的主要内容,在通过YARN运行基于Spark的分布式神经网络训练时,必须要做以下几件事:
在设置这些值的时候,有几点需要注意。 首先,spark.executor.memory与spark.yarn.executor.memoryOverhead之和必须小于YARN所能分配给一个容器的内存量上限。通常这一上限可以在YARN配置或YARN资源管理器网页UI中找到。如果超过这一上限,YARN可能会拒绝您的任务。
其次,org.bytedeco.javacpp.maxbytes的值务必要小于spark.yarn.executor.memoryOverhead。上文曾提到,默认的memoryOverhead设置是执行器内存的10%——这是因为JVM自身(以及其他的库)也可能需要一些堆外内存。因此,我们不能让JavaCPP用完所有的非JVM内存。
第三,由于DL4J/ND4J使用堆外内存来处理数据、参数和激活函数,所以分配给JVM(即executor.memory)的内存量可以比其他状况少一些。当然,我们还需要足够的JVM内存来满足Spark自身(以及我们使用的其他库)的需求,所以也不能减少得太多。
下面来看示例。假设我们在运行Spark训练,想要以如下方式配置内存:
总计堆外内存为5+1=6GB;总内存(JVM + 堆外/额外开销)为4+6=10GB,小于YARN的分配上限11GB。注意JavaCPP的内存是以比特为单位指定的,5GB是5,368,709,120比特;YARN的额外内存开销以MB为单位指定,6GB是6,144MB。
Spark submit参数的指定方式如下:
--class my.class.name.here --num-executors 4 --executor-cores 8 --executor-memory 4G --driver-memory 4G --conf "spark.executor.extraJavaOptions=-Dorg.bytedeco.javacpp.maxbytes=5368709120" --conf "spark.driver.extraJavaOptions=-Dorg.bytedeco.javacpp.maxbytes=5368709120" --conf spark.yarn.executor.memoryOverhead=6144
用Spark本地性配置来改善训练表现
Spark的本地性(locality)设置是一项可选配置,有助于提高训练表现。
总结:为Spark submit配置添加--conf spark.locality.wait=0会让网络的训练操作提早开始,有可能缩短训练时间。
为什么Spark本地性配置可以改善训练表现
Spark有一系列配置选项,用于决定如何控制执行。其中一个重要的部分是有关于本地性的设置。 简而言之,本地性就是指数据相对于其处理地点的位置。假设有一个空闲的执行器,但数据必须跨网络复制才能处理。Spark必须决定是应该执行网络传输,还是应该等待可以在本地访问数据的执行器变为空闲状态。在默认情况下,Spark不会立即将数据跨网络传输至空闲的执行器,而是会稍作等待。这样的默认行为或许适用于其他任务,但在用Deeplearning4j训练神经网络时,这种方式不利于集群利用率的最大化。
深度学习的计算强度大,因此每个输入的DataSet对象的计算量都相对较高。此外,在Spark训练过程中,DL4J会确保每个执行器恰好进行一个任务(分区)。所以,更好的方式始终是立即将数据传输至空闲的执行器,而非等待另一个执行器变为空闲状态。计算时间会超过任何网络传输时间。 让Spark采用这种做法的方式是为Spark submit配置添加--conf spark.locality.wait=0。
更多详情请参阅Spark调试指南-数据本地性和Spark配置指南。
性能调试和训练表现信息收集
Deeplearning4j的Spark训练实现能够收集表现信息(例如创建初始网络、接收广播数据、进行网络训练操作等所需的时间)。 这样的信息可以用于识别和调试在Spark上训练Deeplearning4j网络时出现的任何表现问题。
收集和导出表现信息的代码如下:
SparkDl4jMultiLayer sparkNet = new SparkDl4jMultiLayer(...);
sparkNet.setCollectTrainingStats(true); //启用收集
sparkNet.fit(trainData); //以常规方式训练网络
SparkTrainingStats stats = sparkNet.getSparkTrainingStats(); //获取收集到的统计信息
StatsUtils.exportStatsAsHtml(stats, "SparkStats.html", sc); //导出至独立的HTML文件
请注意,截止到Deeplearning4j的0.6.0版,当前的HTML渲染实现还无法很好地适应大量的统计信息,即大型集群或长期运行的任务。我们正在处理这一问题,未来发布的版本将有所改善。
时间线信息可以通过Spark训练统计信息收集功能获得:
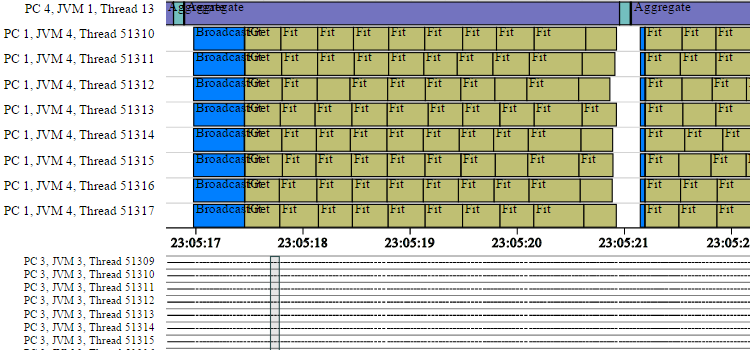
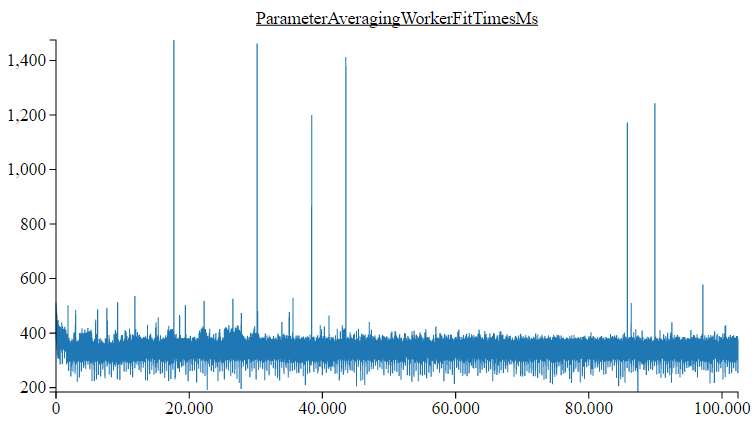
图表之一(工作器fit(DataSet)时间)可以通过Spark Stats获得
调试收集表现信息时出现的“NTP服务器查询错误”
在默认情况下,Spark训练表现统计依赖一项网络时间协议(NTP)实现来确保所有计算机的事件时间戳保持一致, 否则就无法保证每个工作器节点的时钟都是准确的——时钟可能出现任意/未知的误差。如果没有NTP实现,就不可能准确地描绘时间线信息(如上文的时间线图所示)。
有可能会出现NTPTimeSource: Error querying NTP server, attempt 1 of 10这样的错误信息。有时这些错误是暂时的(之后重试可能会恢复正常),可以忽略。 但是,如果Spark集群中有一个或多个工作器无法访问互联网(更具体而言,是无法访问NTP服务器),那么所有重试可能都会出现错误。
有两种解决办法:
如果要用系统时钟作为时间来源,可以将以下代码添加至Spark submit: --conf spark.driver.extraJavaOptions=-Dorg.deeplearning4j.spark.time.TimeSource=org.deeplearning4j.spark.time.SystemClockTimeSource --conf spark.executor.extraJavaOptions=-Dorg.deeplearning4j.spark.time.TimeSource=org.deeplearning4j.spark.time.SystemClockTimeSource
缓存/持久化RDD和RDD
Spark在处理包含大型堆外组件的Java对象,比如Deeplearning4j中使用的DataSet和INDArray对象时,有一些特殊问题需要注意。本段将介绍与这些对象的缓存/持久化相关的问题。
需要了解的要点包括:
为什么推荐使用MEMORY_ONLY_SER或MEMORY_AND_DISK_SER
Apache Spark提高性能的方式之一是允许用户将数据缓存至内存。可以用RDD.cache()或RDD.persist(StorageLevel.MEMORY_ONLY())将数据内容以反序列化(即标准的Java对象)形式存储在内存中。 其基本原理很简单:RDD持久化后,就可以从内存(或者磁盘,取决于具体配置)中调出重复使用,而无需重新计算。但是,内存可能无法完全容纳较大的RDD。在这种情况下,RDD的一些部分必须重新计算或从磁盘中加载,具体取决于持久化时所用的存储级别。此外,为了避免使用过多的内存,Spark会在需要时删除RDD的一些部分(块)。
Spark中可用的主要存储级别如下所列。具体说明参见Spark编程指南。
Spark的问题在于它处理内存的方式。具体来说,Spark在删除RDD的一部分(一块)时,会根据对块的大小的估计来进行判断。而Spark估计块的大小的方式取决于持久化级别。对于MEMORY_ONLY和MEMORY_AND_DISK持久化,估计的方式是遍历Java对象图,即读取一个对象中的字段,以递归方式估计对象大小。但是,这一过程并不会考虑Deeplearning4j或ND4J所使用的堆外内存。对于DataSets和INDArrays这样的对象(几乎完全存储在堆外)而言,Spark的这种估计方法会大大低估它们的真实大小。此外,Spark在决定保留或删除块的时候只会考虑堆内内存的使用量。在使用MEMORY_ONLY和MEMORY_AND_DISK持久化的情况下,由于DataSet和INDArray对象的堆内内存用量很小,Spark会保留过多的这两种对象,导致堆外内存用尽,造成内存不足的问题。
但在MEMORY_ONLY_SER和MEMORY_AND_DISK_SER级别的持久化中,Spark会以序列化形式将块存储在Java堆内。Spark可以准确估计以序列化形式存储的对象大小(序列化对象没有堆外内存部分),因此Spark会在需要时删除一些块,避免出现内存不足的问题。
Kryo序列化与Deeplearning4j并用
Kryo是经常与Apache Spark配合使用的序列化库,据称能通过减少对象序列化所需的时间来提高性能。 但是,Kryo无法很好地适应ND4J的堆外数据结构。若要在Apache Spark上同时使用ND4J和Kryo序列化,就必须对Spark进行一些额外的配置设置。 如果Kryo的配置不正确,某些INDArray可能会出现NullPointerExceptions,原因是错误的序列化。
若要使用Kryo,可以添加合适的nd4j-kryo依赖项,并将Spark配置设为使用Nd4j Kryo Registrator,方法如下:
SparkConf conf = new SparkConf();
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer");
conf.set("spark.kryo.registrator", "org.nd4j.Nd4jRegistrator");
请注意,在使用Deeplearning4j的SparkDl4jMultiLayer或SparkComputationGraph类时,如果Kryo配置不正确,会记录一次警报。
在亚马逊Elastic MapReduce上使用英特尔MKL和Deeplearning4j
Maven中央仓库上发布的DL4J版本采用的是OpenBLAS。因此本段不适用于选择了Maven中央仓库提供的Deeplearning4j的用户。
对于用英特尔MKL作为BLAS库从源码构建的DL4J,还需要一些额外的配置才能在亚马逊Elastic MapReduce上正常运行。 在EMR中创建一个集群时,若要使用英特尔MKL,就必须提供一些额外的配置。
依次进入Create Cluster(创建集群) -> Advanced Options(高级选项) -> Edit Software Settings(编辑软件设置),然后添加以下代码:
[
{
"Classification": "hadoop-env",
"Configurations": [
{
"Classification": "export",
"Configurations": [],
"Properties": {
"MKL_THREADING_LAYER": "GNU",
"LD_PRELOAD": "/usr/lib64/libgomp.so.1"
}
}
],
"Properties": {}
}
]
相关资源
备注
注意!!!Spark在Ubuntu 16.04上的问题可能会影响DL4J用户
在装有Ubuntu 16.04的计算机上的YARN集群中运行Spark时,有可能出现这种情况:完成一项任务后,运行Hadoop/YARN的用户所有的全部进程都被杀死。该问题与Ubuntu的一项bug有关,相关记录参见https://bugs.launchpad.net/ubuntu/+source/procps/+bug/1610499。Stackoverflow上也有关于此问题的讨论,参见http://stackoverflow.com/questions/38419078/logouts-while-running-hadoop-under-ubuntu-16-04。
目前已经有人提出一些解决方法。
方法1:
添加
[login]
KillUserProcesses=no
至/etc/systemd/logind.conf,然后重启。
方法2:
复制并改用Ubuntu 14.04的/bin/kill二进制文件。
方法3:
降级至Ubuntu 14.04
方法4:
在集群节点上运行
sudo loginctl enable-linger hadoop_user_name