DL4J与基于Hadoop和Spark的迭代式归纳
为了便于理解迭代式归纳(Iterative Reduce),可以从问世更早也更简单一些的MapReduce入手。
MapReduce
MapReduce(映射/归纳)是一种在多个处理器核上处理超大型数据集的技术。谷歌的Jeff Dean在一篇2004年的研究论文中首次介绍了这一方法,一年后,雅虎的Doug Cutting实现了一种相似的架构。Cutting的项目最终演变为Apache Hadoop。两个项目最初的设计目的都是对Web进行批量索引,后来又产生了许多其他的应用。
MapReduce这个词指的是函数式编程衍生出的两种方法。Map(映射)操作指对一个值列表中的每项元素进行同样的运算,得到一个新的值列表。Reduce(归纳)操作指将一个列表中的值合并,减少值的个数。
可以通过词汇表词频统计的例子来理解Map和Reduce的最简形式:Map将一个词汇表中的每一个词的每个实例变成值为1的键值对;Reduce则把与每个词相关联的1相加,得到词频。
MapReduce实际运行时规模更大。Map可以分解非常大的任务,将数据分发给许多处理器核,在这些数据分片上运行相同的运算。Reduce将所有分散并转换后的分片合并成一个数据集,把所有结果汇集到一处,进行一项加法运算。Map是膨胀,而Reduce则是坍缩,就像一颗恒星先扩张成红巨星,再收缩成白矮星。
迭代式MapReduce
虽然MapReduce在许多用例中只需单次遍历即可,但这对于机器学习和深度学习来说是不够的,因为模型“学习”的本质就是一项优化算法通过许多次的迭代步骤来达到最小误差。
迭代式MapReduce同样也是受Jeff Dean启发而提出的,可以将其视为一种多次而非单次遍历数据的YARN框架。虽然迭代式归纳的架构与MapReduce有所区别,但总体上而言,可以把它理解为一个MapReduce操作序列,其中MapReduce1的输出成为MapReduce2的输入,以此类推。
假设现在有一个深度置信网络,而您想用一个非常大的数据集来训练,生成能够将输入准确分类的模型。深度置信网络由三个函数组成:一个将输入映射到分类的计分函数、一个衡量模型预测结果与正确答案的差距的误差函数、一个调整模型参数直至预测误差达到最小的优化算法。
Map将以上所有操作置于分布式系统的每个处理器核中。然后它会把规模庞大的输入数据集分批分发给许多处理器核。每个核都用得到的输入训练一个模型。Reduce对所有模型的参数进行平均化,然后将聚合后的新模型发送回每一个核。迭代式归纳将这样的操作重复多次,直至学习结果趋于稳定,误差不再缩小。
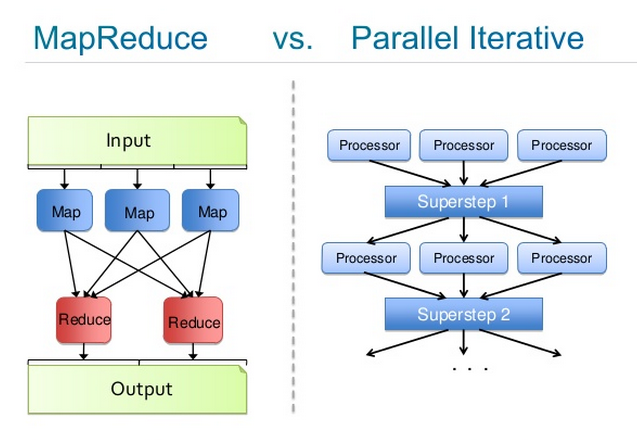
以下这幅由Josh Patterson绘制的示意图比较了这两种流程。左侧是MapReduce的流程详情;右边则是迭代式归纳。每个“处理器(Processor)”都是一个用大型数据集中的多批数据进行学习的深度置信网络;每个“超步(Superstep)”是一次参数平均化,所得的中央模型会被重新分发给整个集群。
Hadoop和Spark
Hadoop和Spark都是能够进行MapReduce和迭代式归纳的分布式运行时。Deeplearning4j作为Hadoop/YARN或Spark中的一项任务运行,比如可以将其作为一项YARN应用来调用、运行和预配。
在Hadoop中,迭代式归纳的工作器负责各自的数据分片,亦即HDFS块,以同步方式并行处理数据,再把变换后的参数发回主节点,主节点将参数平均化,然后用其更新每个工作器的处理器核上的模型。MapReduce的映射路径不会持续保留,而迭代式归纳的工作器则是“常驻”的。Spark的架构与此大致相似。
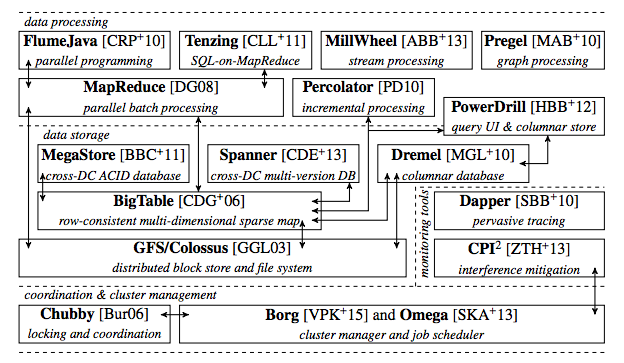
稍微介绍一下这方面技术的最新进展。谷歌和雅虎都运营着存储了海量参数的参数服务器,这些数以亿计的参数会被分发到集群中进行处理。谷歌的系统称为Google Brain,由Andrew Ng创建,现在由他的学生Quoc Le负责领导。以下是2015年前后谷歌生产栈的总体示意图,其中可见MapReduce的定位。
Deeplearning4j认为分布式运行时是可互换的(但不一定完全等同);它们都只是整个模块化架构中的一个目录,可以任意替换。这让整体项目能以不同速度演进,而来自其他模块的独立的运行时可以分别被专用于神经网络算法或硬件。Deeplearning4j也能用Akka构建一个独立的分布式架构,在AWS上组织节点。
包括Hadoop和Spark在内的所有向外扩展形式都收录在我们的向外扩展库中。
比方说,Deeplearning4j的代码可以与Spark相混合,让DL4J也能像其他应用一样实现分布式运行。