MNIST基础教程
本教程将介绍如何对MNIST数据集进行分类,这在机器学习领域是相当于“Hello World”的入门示例。
目录
完成整个过程预计需要30分钟时间。
序言
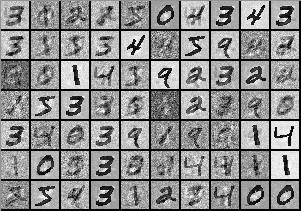
MNIST是一个手写数字图像的数据集,每幅图像都由一个整数标记。它主要用于机器学习算法的性能对标。深度学习算法处理MNIST的效果相当好,准确率可达到99.7%以上。
我们将用MNIST来训练一个神经网络,使之能读取每幅图像并预测其中的数字。首先需要安装Deeplearning4j。
MNIST数据集
MNIST数据集包含一个有6万个样例的训练集和一个有1万个样例的测试集。训练集用于让算法学习如何准确地预测出图像的整数标签,而测试集则用于检查已训练网络的预测有多准确。
这在机器学习领域中被称为有监督学习,因为我们已经知道图像预测所应该得出的正确答案。训练集能起到监督和指导的作用,在神经网络预测错误时予以纠正。
配置MNIST示例
MNIST教程已经打包到Maven当中,所以无需再编写代码。请打开IntelliJ进行准备。(IntelliJ的下载方法请参见快速入门指南)
打开名为dl4j-examples的文件夹。依次进入以下目录src → main → java → feedforward → mnist,打开名为MLPMnistSingleLayerExample.java的文件。
我们将在这个文件中配置神经网络,训练模型,评估结果。建议您结合其中的代码来学习本教程。
设置变量
final int numRows = 28; // 矩阵的行数。
final int numColumns = 28; // 矩阵的列数。
int outputNum = 10; // 潜在结果(比如0到9的整数标签)的数量。
int batchSize = 128; // 每一步抓取的样例数量。
int rngSeed = 123; // 这个随机数生成器用一个随机种子来确保训练时使用的初始权重维持一致。下文将会说明这一点的重要性。
int numEpochs = 15; // 一个epoch指将给定数据集全部处理一遍的周期。
在我们的示例中,每一幅MNIST图像的大小是28x28像素,这意味着输入数据是2 8 numRows x 28 numColumns 的矩阵(矩阵是深度学习的基本数据结构)。其次,MNIST包含10种可能出现的结果(0到9的数字标签),即o utputNum。
batchSize 和 numEpochs必须根据经验选择,而经验则需要通过实验来积累。每批次处理的数据越多,训练速度越快;epoch的数量越多,遍历数据集的次数越多,准确率就越高。
但是,epoch的数量达到一定的大小之后,增益会开始减少,所以要在准确率与训练速度之间进行权衡。总的来说,需要进行实验才能发现最优的数值。本示例中设定了合理的默认值。
抓取MNIST数据
DataSetIterator mnistTrain = new MnistDataSetIterator(batchSize, true, rngSeed);
DataSetIterator mnistTest = new MnistDataSetIterator(batchSize, false, rngSeed);
我们用名为DataSetIterator的类来抓取MNIST中的数据,创建一个用于模型训练的数据集mnistTrain,和另一个用于在训练后评估模型准确率的数据集mnistTest。顺便一提,此处的模型是指神经网络的各种参数。这些参数是用来处理输入数据的系数,神经网络在学习过程中不断调整参数,直至能准确预测出每一幅图像的标签――此时就得到了一个比较准确的模型。
搭建神经网络
我们将按Xavier Glorot和Yoshua Bengio的论文中的描述来建立一个前馈神经网络。在这个基础示例中,我们先搭建一个只有单一隐藏层的神经网络。基本的原则是,深度更深(层数更多)的网络能处理更复杂的数据,捕捉更多细节,进而得出更准确的结果。
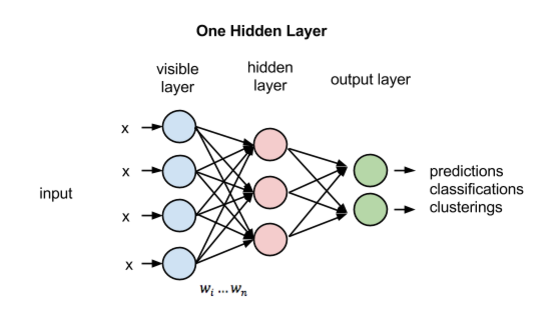
请将上图牢记心中,这就是我们将要搭建的单层神经网络。
设置超参数
不论用Deeplearning4j搭建何种神经网络,其基础都是NeuralNetConfiguration类。我们用这个类来配置各项超参数,其数值决定了网络的架构和算法的学习方式。直观而言,每一项超参数就如同一道菜里的一种食材:取决于食材好坏,这道菜也许非常可口,也可能十分难吃……所幸在深度学习中,如果结果不正确,超参数还可以进行调整。
MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder()
.seed(rngSeed)
.optimizationAlgo(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT)
.iterations(1)
.learningRate(0.006)
.updater(Updater.NESTEROVS).momentum(0.9)
.regularization(true).l2(1e-4)
.list()
.seed(rngSeed)
该参数将一组随机生成的权重确定为初始权重。如果一个示例运行很多次,而每次开始时都生成一组新的随机权重,那么神经网络的表现(准确率和F1值)有可能会出现很大的差异,因为不同的初始权重可能会将算法导向误差曲面上不同的局部极小值。在其他条件不变的情况下,保持相同的随机权重可以使调整其他超参数所产生的效果表现得更加清晰。
.optimizationAlgo (OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT)
随机梯度下降(Stochastic Gradient Descent,SGD)是一种用于优化代价函数的常见方法。要了解SGD和其他帮助实现误差最小化的优化算法,可参考Andrew Ng的机器学习课程以及本网站术语表中对SGD的定义。
.iterations(1)
对一个神经网络而言,一次迭代(iteration)指的是一个学习步骤,亦即模型权重的一次更新。神经网络读取数据并对其进行预测,然后根据预测的错误程度来修正自己的参数。因此迭代次数越多,网络的学习步骤和学习量也越多,让误差更接近极小值。
.learningRate(0.006)
本行用于设定学习速率(learning rate),即每次迭代时对于权重的调整幅度,亦称步幅。学习速率越高,神经网络“翻越”整个误差曲面的速度就越快,但也更容易错过误差极小点。学习速率较低时,网络更有可能找到极小值,但速度会变得非常慢,因为每次权重调整的幅度都比较小。
.updater(Updater.NESTEROVS).momentum(0.9)
动量(momentum)是另一项决定优化算法向最优值收敛的速度的因素。动量影响权重调整的方向,所以在代码中,我们将其视为一种权重的更新器(updater)。
.regularization(true).l2(1e-4)
正则化(regularization)是用来防止过拟合的一种方法。过拟合是指模型对训练数据的拟合非常好,然而一旦在实际应用中遇到从未出现过的数据,运行效果就变得很不理想。
我们用L2正则化来防止个别权重对总体结果产生过大的影响。
.list()
函数可指定网络中层的数量;它会将您的配置复制n次,建立分层的网络结构。
再次提醒:如果对以上任何内容感到困惑,建议您参考Andrew Ng的机器学习课程。
搭建层
我们不会详细解释每项超参数(如activation、weightlnit等)背后的研究;此处仅对超参数的功能定义作简要介绍。若要了解相关研究的详情,请阅读Xavier Glorot和Yoshua Bengio 的论文。
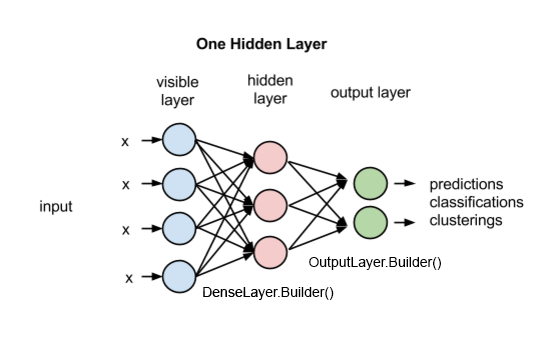
.layer(0, new DenseLayer.Builder()
.nIn(numRows * numColumns) // Number of input datapoints.
.nOut(1000) // Number of output datapoints.
.activation("relu") // Activation function.
.weightInit(WeightInit.XAVIER) // Weight initialization.
.build())
.layer(1, new OutputLayer.Builder(LossFunction.NEGATIVELOGLIKELIHOOD)
.nIn(1000)
.nOut(outputNum)
.activation("softmax")
.weightInit(WeightInit.XAVIER)
.build())
.pretrain(false).backprop(true)
.build();
隐藏层究竟是什么?
隐藏层中的每个节点(上图中的圆圈)表示MNIST数据集中一个手写数字的一项特征。例如,假设现在处理的数字是6,那么一个节点可能表示圆形的边缘,另一个节点可能表示曲线的交叉点,等等。模型的系数按照重要性大小为这些特征赋予权重,随后在每个隐藏层中重新相加,帮助预测当前的手写数字是否确实为6。节点的层数更多,网络就能处理更复杂的因素,捕捉更多细节,进而做出更准确的预测。
之所以将中间的层称为“隐藏”层,是因为人们可以看到数据输入神经网络、判定结果输出,但网络内部的数据处理方式和原理并非一目了然。神经网络模型的参数其实就是包含许多数字、计算机可以读取的长向量。
模型训练
模型已经建立完毕,可以开始训练了。点击IntelliJ界面右上方的绿色箭头,运行上文给出的代码
运行过程需要几分钟时间,具体时长取决于您的硬件情况。
结果评估

| 指示符 | 描述 |
|---|---|
| Accuracy | 准确率:模型准确识别出的MNIST图像数量占总数的百分比。 |
| Precision | 精确率:真正例的数量除以真正例与假正例数之和。 |
| Recall | 召回率:真正例的数量除以真正例与假负例数之和。 |
| F1 Score | F1值:精确率和召回率的加权平均值。 |
精确率、召回率和F1值衡量的是模型的相关性。举例来说,“癌症不会复发”这样的预测结果(即假负例/假阴性)就有风险,因为病人会不再寻求进一步治疗。所以,比较明智的做法是选择一种可以避免假负例的模型(即精确率、召回率和F1值较高),尽管总体上的准确率可能会相对较低一些。
总结
成功了!至此,您已经训练出了一个准确率达到97.1%的神经网络,整个过程不需要任何计算机视觉领域的知识。当前最顶尖的水平比这还要高,您可以借由调整超参数来进一步改善模型的表现。
与其他深度学习框架相比,Deeplearning4j具有以下优点。
- 与Spark、Hadoop、Kafka等主流JVM框架实现大规模集成
- 专为基于分布式CPU和/或GPU运行而优化
- 服务于Java和Scala用户群
- 企业级部署可享商业化支持
若有任何问题,请加入我们的Gitter线上支持交流群。