卷积网络(Convolutional Neural Networks)
目录
卷积网络对图像进行物体辨识,可识别人脸、人类个体、道路标志、茄子、鸭嘴兽以及视觉数据中诸多其他方面的内容。卷积网络与运用光学字符辨识进行的文本分析有重合之处,但也可用于对离散文本单元以及声音形式的文本进行分析。
卷积网络(ConvNets)在图像辨识上的效能,是如今全球对深度学习产生兴趣的重要原因。卷积网络正推动机器视觉的大幅进步,在包括自动驾驶汽车、机器人、无人机和对视觉障碍人士的诊治方面,均具有显而易见的应用价值。
卷积网络采集图像,并将之处理为张量。张量是具有附加维度的数字矩阵。
由于难以对张量进行形象描述,以下将通过类比进行解释。标量是普通数字,比如7;矢量是一串数字(例如:[7,8,9]);而矩阵是像电子表格一样,包含多个行列的数字矩形网格。从几何学角度来说,如果标量是零维定点,那么矢量就是一维直线,矩阵是二维平面,一堆矩阵就是三维立方体。当这些矩阵的每个元素都附着大量的特征映射图时,便进入了四维空间,下面是一个2x2矩阵示例:
[ 1, 2 ]
[ 5, 8 ]
张量涵括了二维平面以上的维度。数组按立方体排列的三维张量很容易想象。所示为水平呈现的2x3x2张量(想象各二元数组的底元素沿Z轴延伸以直观把握三维数组的命名原因):

上述张量可以用代码表示为:[[[2,3],[3,5],[4,7]],[[3,4],[4,6],[5,8]]].请见示意图:
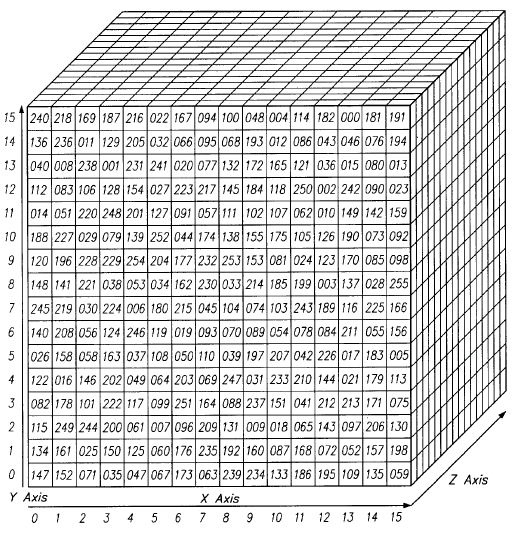
换言之,张量的形成原理为数组嵌套数组。这种嵌套可以无限持续下去,形成远超我们空间想象所能企及的、任意数量的维度。四维张量,即是用嵌套层次更深的数组取代上述各标量。卷积网络对四维张量的处理如下所示(请注意嵌套数组)。
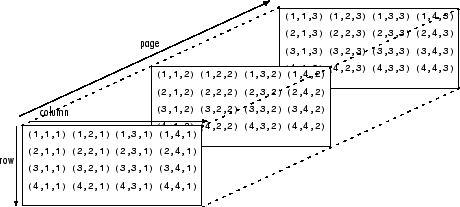
ND4J和Deeplearning4j对NDArray和 “张量” 同义互换使用。张量的维度(1,2,3...n)称为“阶”,也就是说,第五阶张量具有五个维度。
图像的宽度和高度很容易理解。由于颜色的编码方式,必须有一个“深度”。例如,根据红-绿-蓝(RGB)编码,可生成三层深度的图像。每一层也叫作一个“通道”。通过卷积,只需根据时间本身的脉络即可生成存在于第四维的一堆特征映射图(见下文详述)。(所谓特征,即图像的细节信息,如直线或曲线等。卷积网络为特征创建映射图。)
卷积网络将图像按照四维体而非二维面进行处理。上述概念将在下文深入阐述。
英文中的 to convolve 词源为拉丁文 convolvere,意为“卷在一起”。从数学角度说,卷积是指用来计算一个函数通过另一个函数时,两个函数有多少重叠的积分。卷积可以视为通过相乘的方式将两个函数进行混合。
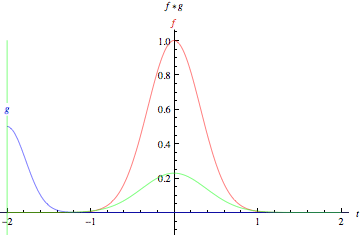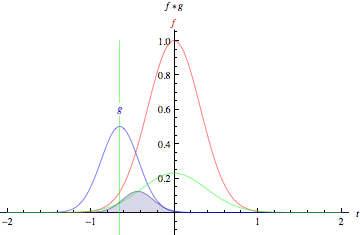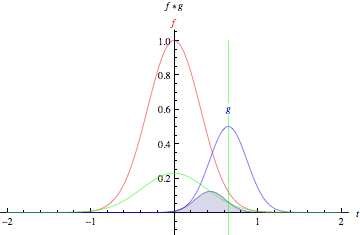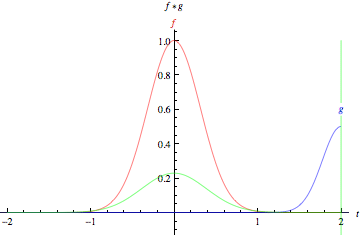
设想在图表中间有一条既高且窄的钟形曲线。曲线下的区域是积分。设想该曲线附近有第二条较短较宽的钟形曲线从图表左侧向右侧缓慢漂移。这两个函数沿X轴各点的重叠部分之积,即是其的卷积。所以在一定意义上,两个函数是被“卷在了一起”。
静态的底层函数是得到分析的输入图像,而动态的另一个函数被称为过滤器,因为该函数会获取图像的信号。两个函数通过乘法产生联系。若想以矩阵而非钟形曲线的方式对卷积进行想象,请见标题“卷积演示”下Andrej Karpathy的极佳动画演示。
我们还需理解,在卷积网络中,一张图像需经过多个过滤器的扫描,每个过滤器获取一个不同的信号。可以想象卷积网络中较早的一层在经过水平线过滤器、垂直线过滤器和对角线过滤器的扫描后,创建了图像边缘的映射图。
卷积网络将这些过滤器获取的图像特征空间片段逐一制成图谱;也就是说,卷积网络为特征出现的各处均创建一张映射图。通过研究特征空间的不同比例,卷积网路可以轻易构建可扩缩且稳健的特征工程。
(请注意,卷积网络分析图像的方式不同于RBM。RBM将各图像视为整体进行特征的重建和识别,而卷积网络对图像片段,亦即“特征映射图”进行分析。)
因此,卷积网络执行的是一种搜索。想象有小型放大镜于较大的图像上从左向右滑动,一遍后再从左边重新开始(如打字机一般)。举例说,该移动窗口仅能识别一截短垂直线。三个暗像素相互堆叠。移动窗口将“垂直线辨识”过滤器在图像的实际像素上进行移动,以寻求匹配。
每次成功的匹配将被绘制于该视觉元素特定的特征空间里。在该空间里,每条垂直线匹配的位置都会得到完整记录,类似鸟类观测员在地图上将最近观测到大蓝鹭的地理位置用大头针进行标记。卷积网络需要在单一图像上运行很多、很多次搜索——无论是水平线,还是对角线,有多少待查的视觉元素,就需要搜索多少次。
卷积网络在输入时,不止仅卷积这项操作。
在经过卷积层处理后,输入信息会经过一次非线性转换,如tanh或者 rectified linear 单元。如此,可以将输入值压缩至-1到1之间。
首先,卷积网络认知图像的方式不同于人类。因此,在图像被卷积网络采集、处理时,需要以不同方式思考其含义。
卷积网络将图像视为体,也即三维物体,而非仅用宽度和高度测量的平面。这是因为,彩色数字图像具有红-绿-蓝(RGB)编码;通过将这三色混合,生成人类肉眼可见的色谱。卷积网络将这些图像作为彼此独立、逐层堆叠的三层色彩进行收集。
故而,卷积网络以矩形接收正常色彩的图像。这一矩形的宽度和高度由其像素点进行衡量,深度则包含三层,每层代表RGB中的一个字母。这些深度层被称为通道。
我们以输入量和输出量来描述经过卷积网络处理的图像,在数学中以多维矩阵表示为:30x30x3。每一层的维度会发生变化,原因详见下文。
需要特别注意图像体各维度的精确测量结果,因为这些结果是用来处理图像的线性代数运算的基础。
对图像的各像素来说,R、G、B的强度将会以数字进行表示。该数字将是三个堆叠二维矩阵之一的元素。图像体由这些二维矩阵一起构成。
这些数字是输入卷积网络的最初原始感官特征,卷积网络意在上述数字中寻找显著信号,从而更精确地对图像进行分类。(就像我们讨论过的其他前馈网络一样。)
卷积网络并非对像素进行逐个处理,而是将包含多像素的方形片块经
感谢Andrej Karpathy提供这一极佳的动画演示。
设想有两个矩阵,一个30x30,另一个3x3。也就是说,过滤器覆盖了图像通道表面积的十分之一。
我们使用这块图像通道得到过滤器的点积。如果两个矩阵在相同位置均具有较高的值,则点积输出会很高。反之,则输出会很低。如此,通过一个单值(即点积输出)便可以确定底层图像的像素图案是否符合过滤器所表示的像素图案。
设想过滤器表示的是一条水平线,其中第二行的值较高,第一、三行的值较低。现从底层图像左上角开始,逐步在图像上移动过滤器直至到达右上角。移动的幅度称为步幅。可每次以一列为单位向右移动过滤器,也可选择更大的步幅。
在每一步获取一个点积,并将点积结果置于被称为激活映射图的第三个矩阵中。激活映射图上的宽度(或列数)与过滤器在底层图像上移动的步数一致。因为步幅越大,步数越小,所以步幅大则激活映射图小。这点之所以重要,是因为卷积网络在各层处理并生成的矩阵的尺寸,与计算成本及所需时间是呈正比的。步幅较大,则所需时间和计算量较小。
置于前三行上的过滤器将经过这三行,而后再经过图像上的第4~6行。若步幅为三,那么生成的点积矩阵为10x10。代表水平线的相同过滤器也可用于底层图像的所有三个通道,亦即R、G和B。三个10x10的激活映射图可以叠加,因此底层图像三个通道上水平线的总体激活映射图也是10x10。
由于图像上不同指向的线非常多,而且图像包含许多不同的形状和像素图案,因此需要使用其他过滤器扫描底层图像,以搜索这些图案。举例说,可以在像素中搜索96种不同图案。这96种图案可构成96张激活映射图,生成10x10x96的新体。在下图中,我们对输入图像、内核和输出的激活映射图重新作了标明。
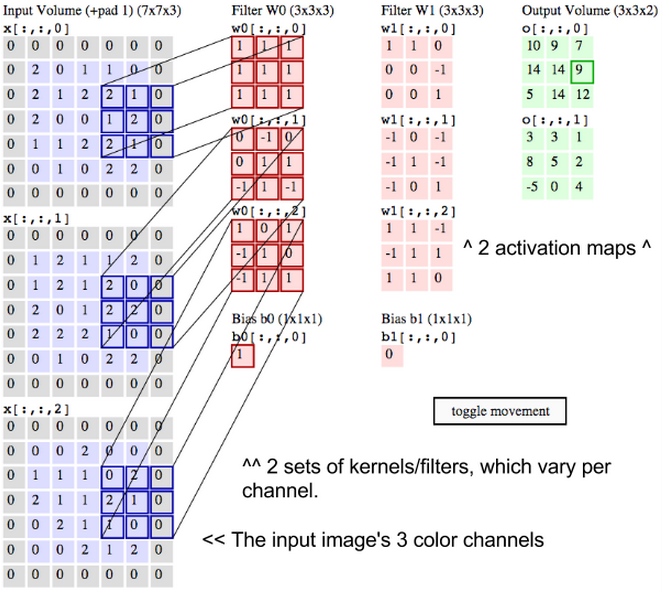
我们刚才描述的即是卷积。可以把卷积想象为信号处理中的一种奇特乘法。也可将两个矩阵生成点积想象为两个函数。图像就是底层函数,而过滤器就是在其上“卷过”的函数。
图像的主要问题在于其高维度,原因是对高维度的处理时间和运算能力成本很高。卷积网络就是为了通过各种方式降低图像的维度而设计的。过滤器步幅即是减少维度的一种方法,另一种方法是降采样。
卷积网络的下一层有三个名称:最大池化、降采样和二次抽样。如卷积的方法一样,将激活映射图每次一个片块地输入降采样层。最大池化仅取图像一个片块的最大值,将之置于存有其他片块最大值的矩阵中,并放弃激活映射图中所载的其他信息。
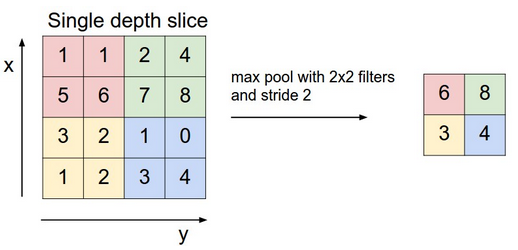
仅保留图像中与各特征(最大值)相关性最大的位置。这些最大值一起构成了一个较低维度的空间。
这一步骤会损失关于较低值的许多信息。这也激发了对替代方法的研究。不过,正因为信息的损失,降采样也有所需存储空间和处理过程较少的优势。
下图是另一种显示典型卷积网络所涉转换顺序的方式。
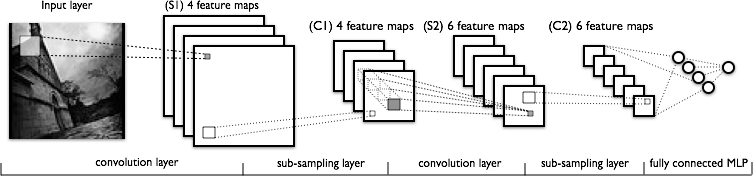
从左至右:
- 为采集特征而得到扫描的实际输入图像。浅灰色矩形是扫描图像的过滤器。
- 逐层叠堆的激活映射图;每一层为一个得到使用的过滤器。较大的矩形是待降采样的片块。
- 通过降采样压缩的激活映射图。
- 通过使过滤器扫描首个已被降采样的映射图堆而得到的一组新激活映射图。
- 压缩第二组激活映射图的第二次降采样。
- 一节点一标记对输出进行分类的完全连接层。
随着信息损失增多,由卷积网络处理的图案变得更为抽象,与人类肉眼所能识别图案之间的差异也变得更大。故而,如果随着卷积网络的深入发展,以致无法简单地用直觉进行理解,也不必担心。
Create an iterator using the batch size for one iteration
*/
log.info("Load data....");
DataSetIterator mnistTrain = new MnistDataSetIterator(batchSize,true,12345);
DataSetIterator mnistTest = new MnistDataSetIterator(batchSize,false,12345);
/*
Construct the neural network
*/
log.info("Build model....");
MultiLayerConfiguration.Builder builder = new NeuralNetConfiguration.Builder()
.seed(seed)
.iterations(iterations) // Training iterations as above
.regularization(true).l2(0.0005)
/*
Uncomment the following for learning decay and bias
*/
.learningRate(.01)//.biasLearningRate(0.02)
//.learningRateDecayPolicy(LearningRatePolicy.Inverse).lrPolicyDecayRate(0.001).lrPolicyPower(0.75)
.weightInit(WeightInit.XAVIER)
.optimizationAlgo(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT)
.updater(Updater.NESTEROVS).momentum(0.9)
.list()
.layer(0, new ConvolutionLayer.Builder(5, 5)
//nIn and nOut specify depth. nIn here is the nChannels and nOut is the number of filters to be applied
.nIn(nChannels)
.stride(1, 1)
.nOut(20)
.activation("identity")
.build())
.layer(1, new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.MAX)
.kernelSize(2,2)
.stride(2,2)
.build())
.layer(2, new ConvolutionLayer.Builder(5, 5)
//Note that nIn need not be specified in later layers
.stride(1, 1)
.nOut(50)
.activation("identity")
.build())
.layer(3, new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.MAX)
.kernelSize(2,2)
.stride(2,2)
.build())
参考这里
- 纽约大学教授、Facebook研究主管Yann Lecun对机器视觉任务中常用的卷积网络使用的推动和发展贡献良多。
- Andrej Karpathy的斯坦福大学课程讲授卷积网络,相当精彩。我们强烈推荐将之作为卷积网络重要概念的入门。(包括Python练习。)
- 此处为我们卷积网络的Github测试。
- 欲一睹DL4J卷积网络的运行实况,请根据快速入门指南运行我们的示例。
- 递归网络简介