DL4J中的循环网络
本页将简要介绍循环网络的具体定型功能,以及如何在DeepLearning4J中实际运用这些功能。本页并非循环神经网络(RNN)的基础教程,读者应对RNN及其用途有基本的了解,且熟悉相关术语。如果读者是首次接触RNN,请先阅读循环网络和LSTM教程,再学习本页内容。
目录
基础内容:数据和网络配置
DL4J目前支持以下各类循环神经网络 * GravesLSTM(长短期记忆) * BidirectionalGravesLSTM(双向长短期记忆) * BaseRecurrent
每种网络均有Java文档可供参考:GravesLSTM、 BidirectionalGravesLSTM、BaseRecurrent
RNN的数据
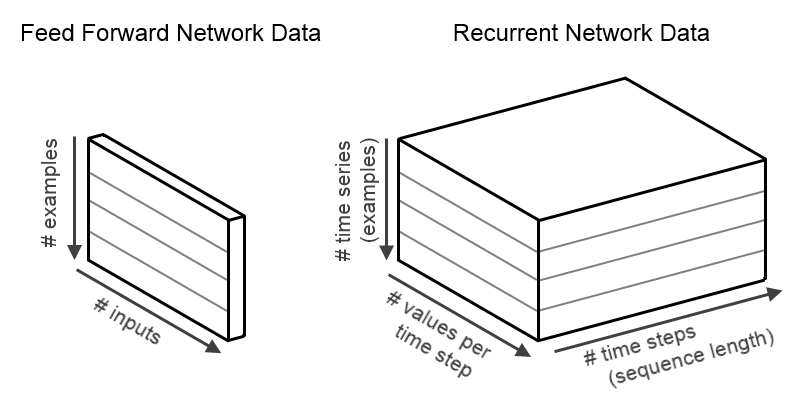
在标准的前馈网络中(多层感知器或DL4J的’DenseLayer’),输入和输出数据具有二维结构,或者说数据的“形状”可以描述为[numExamples, inputSize],即输入前馈网络的数据的行/样例数为’numExamples’,而每一行中的列数为’inputSize’。单个样例的形状应为[1,inputSize],但在实际应用中,为了保证运算和优化的效率,通常会使用多个样例。与此类似,标准前馈网络的输出数据同样具有二维结构,形状为[numExamples,outputSize]。
而RNN的数据则是时间序列。这些数据具备三个维度,增加了一个时间维度。因此,输入数据的形状为[numExamples,inputSize,timeSeriesLength],而输出数据的形状为[numExamples,outputSize,timeSeriesLength]。就INDArray中的数据布局而言,位于(i,j,k)的值即是一批数据中第i例的第k个时间步的第j个值。数据布局如下图所示。
RnnOutputLayer
RnnOutputLayer是在许多循环网络系统(用于回归和分类任务)中使用的最终层。RnnOutputLayer可处理计分运算、基于给定损失函数的误差计算(预测与实际值对比)等。从功能上看,它与“标准”的OutputLayer类(用于前馈网络)十分相似;但RnnOutputLayer的输出(以及标签/目标)均为三维时间序列数据集。
RnnOutputLayer配置与其他层采取相同的设计:例如,将MultiLayerNetwork的第三层设置为RnnOutputLayer,用于分类:
.layer(2, new RnnOutputLayer.Builder(LossFunction.MCXENT).activation("softmax")
.weightInit(WeightInit.XAVIER).nIn(prevLayerSize).nOut(nOut).build())
有关RnnOutputLayer的实际应用,可参考本页末尾处链接指向的相关示例。
RNN定型功能
截断式沿时间反向传播
神经网络(包括RNN)定型的运算能力要求可能相当高。循环网络在处理较长序列时(即定型数据有许多时间步时)尤其如此。
采用截断式沿时间反向传播算法(BPTT)可以降低循环网络中每项参数更新的复杂度。简而言之,此种算法可以让我们以同样的运算能力更快地定型神经网络(提高参数更新的频率)。我们建议在输入较长序列时(通常指超过几百个时间步)使用截断式BPTT算法。
假设用长度为12个时间步的时间序列定型一个循环网络。我们需要进行12步的正向传递,计算误差(基于预测与实际值对比),再进行12个时间步的反向传递:
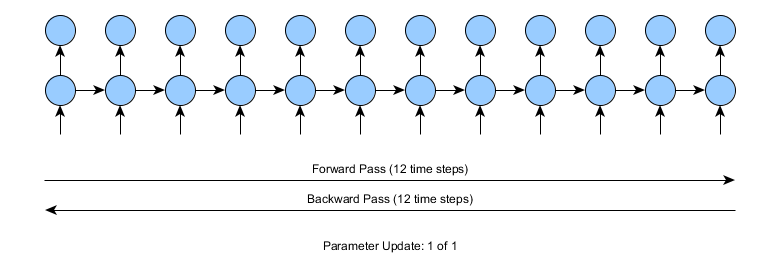
如上图所示,12个时间步的运算不会有问题。但试想输入的时间序列变为10,000个时间步,甚至更多。此时,若使用标准的沿时间反向传播算法,则每个参数每次更新都需要进行10,000次正向及反向传递。这种方法对运算能力的要求显然很高。
在实际应用中,截断式BPTT可将正向和反向传递拆分为一系列较小时间段的正向/反向传递操作。正向/反向传递时间段的具体长度是用户可以自行设定的参数。例如,若将截断式BPTT的长度设定为4个时间步,则学习过程如下图所示:
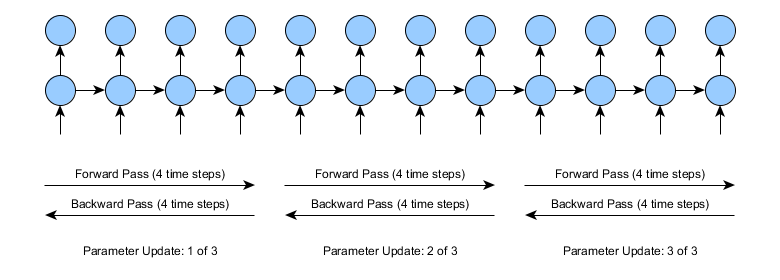
注意截断式BPTT和标准BPTT的总体复杂度大致相同-两者的正向/反向传递时间步数量相等。但是,采用该方法后,用原来1次参数更新的工作量可以完成3次更新。然而两种方法的运算量并不完全一致,因为每次参数更新会有少量额外运算量。
截断式BPTT的不利之处在于,通过这种方法习得的依赖长度可能短于完整BPTT。原因很明显。以上图中长度为4的截断式BPTT为例。假设在第10个时间步时,网络需要存储一些来自第0时间步的信息来做出准确的预测。这在标准BPTT中可以实现:梯度可沿着展开的网络反向流动,从第10步一直到第0步。而截断式BPTT则会出现问题:第10时间步的梯度反向流动的距离不够远,无法完成存储必要信息所需的参数更新。通常情况下,截断式BPTT方法利大于弊,而且(只要长度设定合适)在实际应用中效果良好。
在DL4J中使用截断式BPTT相当简单:只需将下列代码加入网络配置(添加在网络配置最后的.build()之前)
.backpropType(BackpropType.TruncatedBPTT)
.tBPTTForwardLength(100)
.tBPTTBackwardLength(100)
上述代码片段将令任意网络定型(即调用MultiLayerNetwork.fit()方法)使用截断式BPTT,正向与反向传递长度均为100。
注意事项:
- 在默认情况下(未手动设置反向传播类型),DL4J将使用BackpropType.Standard(即完整BPTT)。
- tBPTTForwardLength和tBPTTBackwardLength选项用于设置截断式BPTT传递的长度。时间段长度通常设定为50~200,但需要视具体应用而定。正向传递与反向传递的长度通常相同(有时tBPTTBackwardLength可能更短,但不会更长)
- 截断式BPTT的长度必须短于或等于时间序列的总长
掩模:一对多、多对一和序列分类
DL4J支持一系列基于填零和掩模操作的RNN定型功能。填零和掩模让我们能支持诸如一对多、多对一数据情景下的定型,同时也能支持长度可变的时间序列(同一批次内)。
假设我们用于定型循环网络的输入和输出数据并不会在每个时间步都出现。具体示例(单个样例)见下图。DL4J支持以下所有情景的网络定型。
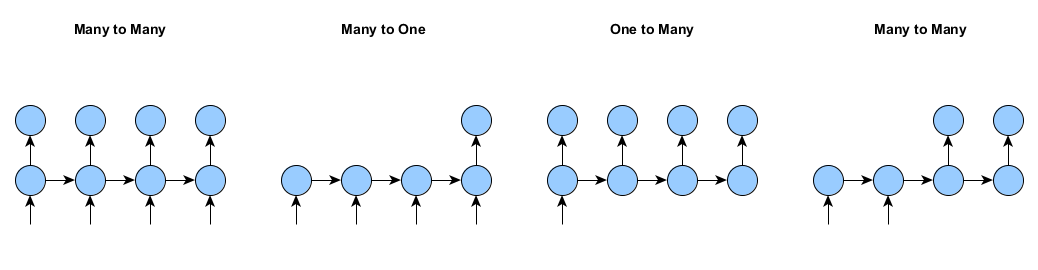
如果没有掩模和填零操作,就只能支持多对多的情景(上图左一),即(a)所有样例长度相同且(b)样例在每一时间步均有输入和输出。
填零的概念很简单。试想同一批次中有两个长度分别为50和100个时间步的时间序列。定型数据是一矩形数组;因此我们对较短的时间序列(输入和输出)进行填零操作(即添加零),使输入和输出长度相等(在本例中为100时间步)。
当然,只进行这一操作会导致定型出现问题。因此在填零之外,我们还使用掩模机制。掩模的概念也很简单:我们增加两个数组,用来记录一个时间步和样例的输入/输出是实际的输入/输出还是填零。
如前文所述,RNN的批次数据有3个维度,输入和输出的形状为[miniBatchSize,inputSize,timeSeriesLength]和 [miniBatchSize,outputSize,timeSeriesLength]。而填零数组则是二维结构,输入和输出的形状均为[miniBatchSize,timeSeriesLength],每一时间序列和样例对应的值为0(“不存在”)或1(“存在”)。输入与输出的掩模数组分开存储在不同的数组中。
对单个样例而言,输入与输出的掩模数组如下:
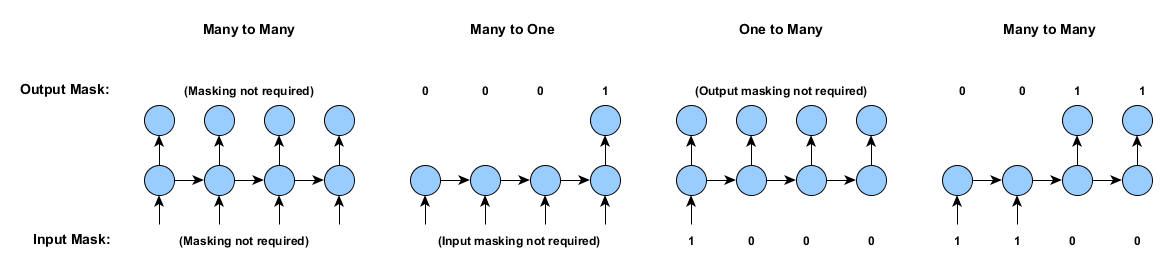
对于“不需要掩模”的情况,我们可以使用全部值为1的掩模数组,所得结果与不使用掩模数组相同。此外,RNN定型中使用的掩模数组可以是零个、一个或者两个,比如多对一的情景就有可能仅设置一个用于输出的掩模数组。
实际应用中,填零数组一般在数据导入阶段创建(例如由SequenceRecordReaderDatasetIterator创建,后文将具体介绍),包含在DataSet对象中。如果一个DataSet包含掩模数组,MultiLayerNetwork在定型中会自动使用。如果不存在掩模数组,则不会启用掩模功能。
使用掩模的评估与计分
掩模数组在进行计分与评估时(如评估RNN分类器的准确性)也很重要。以多对一情景为例:每个样例仅有单一输出,任何评估都应考虑到这一点。
在评估中可通过以下方法使用(输出)掩模数组:
Evaluation.evalTimeSeries(INDArray labels, INDArray predicted, INDArray outputMask)
其中labels是实际输出(三维时间序列),predicted是网络的预测(三维时间序列,与labels形状相同),而outputMask则是输出的二维掩模数组。注意评估并不需要输入掩模数组。
得分计算同样会通过MultiLayerNetwork.score(DataSet)方法用到掩模数组。如前文所述,如果DataSet包括一个输出掩模数组,计算网络得分(损失函数 - 均方差、负对数似然函数等)时就会自动使用掩模。
掩膜与定型后的序列分类
序列分类是掩膜的常见用途之一。之所以采用掩膜,是因为循环网络的输入是序列(时间序列),而我们只需要为整个序列加一个标签(而不是为序列中的每个时间步都加一个标签)。
但是,根据RNN的设计,网络输出的序列应与输入序列长度相等。有了掩膜,我们在定型用于序列分类的网络时就可以将整个序列的标签置于最后一个时间步——其本质就是让网络知道标签数据实际上只出现在最后一个时间步。
假设网络已定型完毕,现在我们希望从时间序列的输出数组中获取最后一个时间步的预测结果。该怎样操作呢?
要获取最后一个时间步的结果,需要考虑两种不同的情形。首先,如果只有单个样例,那我们就不需要使用掩膜数组,可以直接获取输出数组中最后一个时间步的结果:
INDArray timeSeriesFeatures = ...;
INDArray timeSeriesOutput = myNetwork.output(timeSeriesFeatures);
int timeSeriesLength = timeSeriesOutput.size(2); //时间维度大小
INDArray lastTimeStepProbabilities = timeSeriesOutput.get(NDArrayIndex.point(0), NDArrayIndex.all(), NDArrayIndex.point(timeSeriesLength-1));
假设现在处理的是分类问题(但回归问题的流程也一样),上述最后一行代码会给出最后一个时间步的概率,亦即序列分类的类别概率。
另一种更复杂的情形是一个微批次(特征数组)中包含了多个样例,而样例的长度各不相同(如果样例长度相同,则可以使用前一种流程)。
在样例长度有差异的情形中,我们需要分别获取各个样例在最后一个时间步的结果。如果数据加工管道为我们提供了每个样例的时间序列长度,那就比较好办:只需对样例进行迭代 ,将前文代码中的```timeSeriesLength```换成样例长度即可。
假如无法直接获取时间序列的长度,我们就需要将其从掩膜数组中提取出来。
如果有标签掩膜数组(每个时间序列相对应的one-hot向量,形如[0,0,0,1,0]):
INDArray labelsMaskArray = ...;
INDArray lastTimeStepIndices = Nd4j.argMax(labelMaskArray,1);
假如只有特征掩膜,一种比较直截了当的处理方法是:
INDArray featuresMaskArray = ...;
int longestTimeSeries = featuresMaskArray.size(1);
INDArray linspace = Nd4j.linspace(1,longestTimeSeries,longestTimeSeries);
INDArray temp = featuresMaskArray.mulColumnVector(linspace);
INDArray lastTimeStepIndices = Nd4j.argMax(temp,1);
可以这样理解上述方法的原理:我们有形如[1,1,1,1,0]的特征掩膜,现在要从中提取出最后一个非零元素。所以我们将[1,1,1,1,0]映射为[1,2,3,4,0],然后提取其中最大的元素(即最后一个时间步)。
无论是哪种情形,接下来的步骤都可以是:
int numExamples = timeSeriesFeatures.size(0);
for( int i=0; i<numExamples; i++ ){
int thisTimeSeriesLastIndex = lastTimeStepIndices.getInt(i);
INDArray thisExampleProbabilities = timeSeriesOutput.get(NDArrayIndex.point(i), NDArrayIndex.all(), NDArrayIndex.point(thisTimeSeriesLastIndex));
}
RNN层与其他神经网络层的结合应用
DL4J中的RNN层可以与其他类型的层结合使用。例如,可以在同一个网络结合使用DenseLayer和GravesLSTM层;或者将卷积(CNN)层与GravesLSTM层结合用于处理视频。
当然,DenseLayer和卷积层并不处理时间序列数据-这些层要求的输入类型不同。为了解决这一问题,我们需要使用层预处理器功能:比如CnnToRnnPreProcessor和FeedForwardToRnnPreprocessor类。点击此处查看所有预处理器。大部分情况下,DL4J配置系统会自动添加所需的预处理器。但预处理器也可以手动添加(替代为每一层自动添加的预处理器)。
例如,如需在第1和第2层之间添加预处理器,可在网络配置中添加下列代码:.inputPreProcessor(2, new RnnToFeedForwardPreProcessor()).
测试时间:逐步预测
同其他类型的神经网络一样,RNN可以使用MultiLayerNetwork.output() 和MultiLayerNetwork.feedForward() 方法生成预测。这些方法适用于诸多情况;但它们的限制是,在生成时间序列的预测时,每次都只能从头开始运算。
假设我们需要在一个实时系统中生成基于大量历史数据的预测。在这种情况下,使用output/feedForward方法是不实际的,因为这些方法每次被调用时都需要进行所有历史数据的正向传递。如果我们要在每个时间步进行单个时间步的预测,那么此类方法会导致(a)运算量很大,同时(b)由于重复同样的运算而造成浪费。
对于此类情况,MultiLayerNetwork提供四种主要的方法:
rnnTimeStep(INDArray)rnnClearPreviousState()rnnGetPreviousState(int layer)rnnSetPreviousState(int layer, Map<String,INDArray> state)
rnnTimeStep()方法的作用是提高正向传递(预测)的效率,一次进行一步或数步预测。与output/feedForward方法不同,rnnTimeStep方法在被调用时会记录RNN各层的内部状态。需要注意的是,rnnTimeStep与output/feedForward方法的输出应当完全一致(对每个时间步而言),不论是同时进行所有预测(output/feedForward)还是一次只生成一步或数步预测(rnnTimeStep),唯一的区别就是运算量不同。
简言之,MultiLayerNetwork.rnnTimeStep()方法有以下两项作用:
- 用事先存储的状态(如有)生成输出/预测(正向传递)
- 更新已存储的状态,记录上一个时间步的激活情况(准备在下一次调用rnnTimeStep时使用)
例如,假设我们需要用一个RNN来预测一小时后的天气状况(假定输入是前100个小时的天气数据)。 如果采用output方法,那么我们需要送入全部100个小时的数据,才能预测出第101个小时的天气。而预测第102个小时的天气时,我们又需要送入100(或101)个小时的数据;第103个小时及之后的预测同理。
或者,我们可以使用rnnTimeStep方法。当然,在进行第一次预测时,我们仍需要使用全部100个小时的历史数据,进行完整的正向传递:
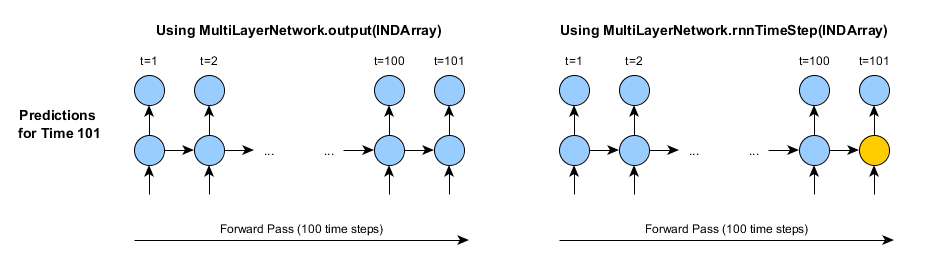
首次调用rnnTimeStep时,唯一实际区别就是上一个时间步的激活情况/状态会被记录下来-图中以橙色表示。但是,第二次使用rnnTimeStep方法时,已存储的状态会被用于生成第二次预测:
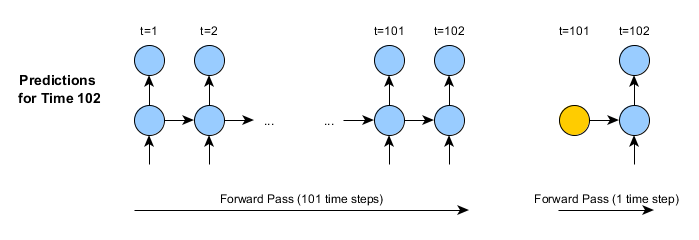
这里有几个重要的区别:
- 在第二张图片中(第二次调用rnnTimeStep),输入数据仅为单个时间步,而非所有的历史数据。
- 因此,正向传递只包括一个时间步(而不是几百个或更多)
- rnnTimeStep方法返回后,内部状态会自动更新。所以第103个时间步的预测方式与第102步相同。以此类推。
但如果要开始对一个新的(完全分离的)时间序列进行预测,就必须(这很重要)用MultiLayerNetwork.rnnClearPreviousState()方法手动清除已存储的状态。该方法将会重置网络中所有循环层的内部状态。
如果需要存储或设置RNN的内部状态以用于预测,可以对每一层分别使用rnnGetPreviousState和rnnSetPreviousState方法。这适用于例如序列化(网络保存/加载)等情况,因为由rnnTimeStep方法产生的内部网络状态默认不会保存,必须另外保存和读取。注意这些获取/设置状态的方法返回和接受的是一张映射图,关键字为激活类型。例如,在LSTM模型中,必须同时存储输出激活情况和记忆单元状态。
其他注意事项:
- 可以用rnnTimeStep方法同时处理多个独立的样例/预测。比如在上文提到的天气预测案例中,就可以使用同个神经网络对多个地点开展预测。运作方式与定型以及正向传递/输出方法相同:多个行(输入数据中的第零维度)用于多个样例。
- 如果未设置历史/已存储状态(最初或在调用rnnClearPreviousState后),则会使用默认初始值(零)。这与定型时的方式相同。 rnnTimeStep可以同时用于任意数量的时间步,而不仅仅是一个时间步。但必须注意的是:
- 在单个时间步预测中,数据具有[numExamples,nIn]的二维形状;此时的输出也是二维结构,形状为[numExamples,nOut]
- 在多个时间步预测中,数据具有[numExamples,nIn,numTimeSteps]的三维形状;此时输出形状为[numExamples,nOut,numTimeSteps]。如前文所述,最后一个时间步的激活情况会像之前一样被存储。
- 样例的数量在两次调用rnnTimeStep之间无法改变(换言之,如果第一次使用rnnTimeStep时的样例数量为3,那么此后每次调用时的样例都必须是3个)。重置内部状态后(使用rnnClearPreviousState()),下一次调用rnnTimeStep可选用任意数量的样例。
- rnnTimeStep方法不改变参数;该方法仅在网络定型已经完成后使用。
- rnnTimeStep方法适用于包含单个和堆叠/多个RNN层的网络,也适用于RNN与其他类型的层(例如卷积或稠密层)相结合的网络。
- RnnOutputLayer类型的层没有任何循环连接,因此不存在内部状态。
导入时间序列数据
RNN的数据导入比较复杂,因为可能使用的数据类型较多:一对多、多对一、长度可变的时间序列等。本节将介绍DL4J目前已实现的数据导入机制。
此处介绍的方法采用SequenceRecordReaderDataSetIterator class类,以及DataVec的CSVSequenceRecordReader类。该方法目前可加载来自文件的已分隔(用制表符或逗号)数据,每个时间序列为一个单独文件。 该方法还支持:
- 长度可变的时间序列输入
- 一对多和多对一数据加载(输入和标签在不同文件内)
- 分类问题中,由索引到one-hot表示方法的标签转换(如从“2”到[0,0,1,0])
- 在数据文件开始处跳过固定/指定数量的行(如注释或标题行)
注意在所有情况下,数据文件中的每一行都表示一个时间步。
(除了下文的示例外,还可参考这些单元测试。)
示例1:等长时间序列,输入和标签在不同文件内
假设定型数据中有10个时间序列,以20个文件表示:10个文件为每个时间序列的输入,10个文件为输出/标签。现在暂时假设这20个文件都包含同样数量的时间步(即行数相同)。
为了使用SequenceRecordReaderDataSetIterator和CSVSequenceRecordReader方法,首先要创建两个CSVSequenceRecordReader对象,一个用于输入,一个用于标签:
SequenceRecordReader featureReader = new CSVSequenceRecordReader(1, ",");
SequenceRecordReader labelReader = new CSVSequenceRecordReader(1, ",");
这一构造方法指定需要跳过的行数(此处跳过1行)和分隔符(此处使用逗号)。
其次,我们需要将这两个读取器初始化,指示它们从何处获取数据。这一步可以用InputSplit对象完成。 假设我们的时间序列带有编号,文件名如“myInput_0.csv”、“myInput_1.csv”、……“myLabels_0.csv”等。方法之一是使用NumberedFileInputSplit:
featureReader.initialize(new NumberedFileInputSplit("/path/to/data/myInput_%d.csv", 0, 9));
labelReader.initialize(new NumberedFileInputSplit(/path/to/data/myLabels_%d.csv", 0, 9));
在这一方法中,“%d”被相应的数字替代, 此处使用数字0~9(包括0和9)。
最后,我们可以创建自己的SequenceRecordReaderdataSetIterator:
DataSetIterator iter = new SequenceRecordReaderDataSetIterator(featureReader, labelReader, miniBatchSize, numPossibleLabels, regression);
随后DataSetIterator可以传递给MultiLayerNetwork.fit(),用于网络定型。
参数miniBatchSize指定每个批次中的样例(时间序列)数量。例如,若文件数为10,miniBatchSize为5, 我们将得到两个数据集,共有2个批次(DataSet对象),每批次有5个时间序列。
请注意:
- 分类问题中,numPossibleLabels是数据集内类的数量。应指定regression = false。
- 标签数据:每行一个值,作为类索引
- 标签数据会被自动转换为one-hot表示方法
- 回归问题中,不使用numPossibleLabels(可任意指定值),应指定regression = true。
- 可以处理任意数量的输入与标签值(与分类不同,可以处理任意数量的输出)
- 指定regression = true时不会对标签进行处理
示例2:等长时间序列,输入和标签在同个文件内
接前一示例,现假设输入数据和标签并非位于不同的文件内,而是存放于同个文件中。但每个时间序列仍然位于一个单独的文件内。
截止到DL4J 0.4-rc3.8版本,这一方法仅限于处理单列输出(一个类索引或者单一实数值的回归输出)
此时需创建单个读取器并将之初始化。和前一例相同,我们跳过一个标题行,指定格式为按逗号分隔,同时假设数据文件命名为“myData_0.csv”,……,“myData_9.csv”:
SequenceRecordReader reader = new CSVSequenceRecordReader(1, ",");
reader.initialize(new NumberedFileInputSplit("/path/to/data/myData_%d.csv", 0, 9));
DataSetIterator iterClassification = new SequenceRecordReaderDataSetIterator(reader, miniBatchSize, numPossibleLabels, labelIndex, false);
miniBatchSize和numPossibleLabels与前一例相同。此处的labelIndex指定标签所在的列。 比如,若标签在第五列,则指定labelIndex = 4(即列的索引值为0到numColumns-1)。
在单一输出值的回归中,我们使用:
DataSetIterator iterRegression = new SequenceRecordReaderDataSetIterator(reader, miniBatchSize, -1, labelIndex, true);
如前文所述,回归中不使用numPossibleLabels参数。
示例3:不等长时间序列(多对多)
接前两例,假设每个单独样例的输入和标签长度相等,但不同的时间序列之间则存在长度差异。
我们可以使用同样的方法(CSVSequenceRecordReader and SequenceRecordReaderDataSetIterator),但需要改变构造器:
DataSetIterator variableLengthIter = new SequenceRecordReaderDataSetIterator(featureReader, labelReader, miniBatchSize, numPossibleLabels, regression, SequenceRecordReaderDataSetIterator.AlignmentMode.ALIGN_END);
此处的参数与前一示例相同,区别在于添加了AlignmentMode.ALIGN_END。这一对齐模式输入让SequenceRecordReaderDataSetIterator做好以下两项准备:
- 获知时间序列的长度可能不相等
- 将每个单独样例中的输入与标签进行对齐,使其最终值出现在同一个时间步。
注意,如果特征与标签的长度始终相同(如示例3的假设),则两个对齐模式(AlignmentMode.ALIGN_END和AlignmentMode.ALIGN_START)会给出完全相同的输出。对齐模式选项会在下一节中介绍。
另外请注意,长度可变的时间序列始终从数据组中第0时间步开始,如需要填零,则会在时间序列结束后添加零。
与示例1和2不同,上述variableLengthIter样例产生的DataSet对象还将包括输入和掩模数组,如前文所述。
示例4:多对一和一对多数据
示例3中的AlignmentMode功能还可以用于实现多对一的RNN序列分类器。让我们假设:
- 输入和标签各位于不同的已分隔文件内
- 标签文件包含单个行(时间步)(分类用的类索引,或者一个或多个回归数值)
- 不同样例的输出长度有可能不相同(可选)
示例3中的同一方法其实还可以如下操作:
DataSetIterator variableLengthIter = new SequenceRecordReaderDataSetIterator(featureReader, labelReader, miniBatchSize, numPossibleLabels, regression, SequenceRecordReaderDataSetIterator.AlignmentMode.ALIGN_END);
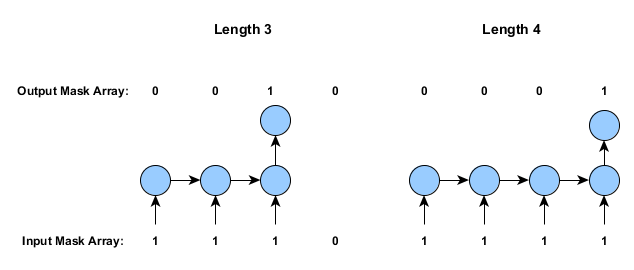
对齐模式相对容易理解。它们指定是在较短时间序列的起始还是结尾处填零。下图描述了这一过程,并标出掩模数组(如本页前文所述):
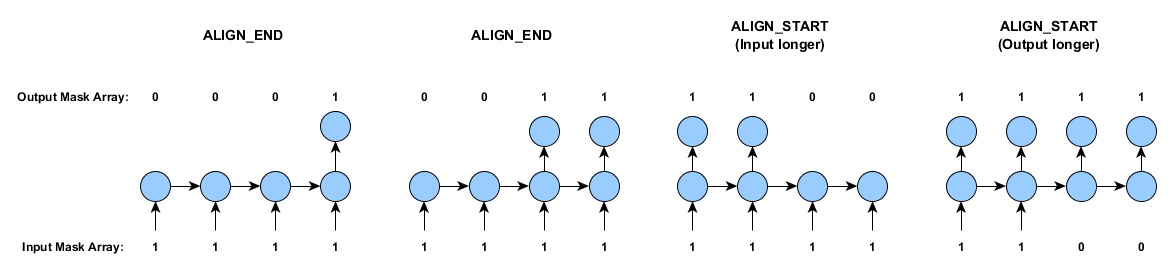
一对多情景(与前一例相仿,但输入仅有一个)可以用AlignmentMode.ALIGN_START来处理。
注意,在定型数据包含非等长时间序列的情况下,各个样例的标签和输入会被分别对齐,随后会按需要对较短的时间序列进行填零。
替代方法:运用自定义DataSetIterator
有些时候,我们可能需要进行不符合常规情景的数据导入。方法之一是运用自定义的DataSetIterator。DataSetIterator只是用于迭代DataSet对象的接口,这些对象封装了输入和目标INDArrays,以及输入和标签掩模数组(可选)。
需要注意的是,这一方法的级别较低:运用DataSetIterator时,必须手动创建所需的输入和标签INDArrays,以及输入和标签掩模数组(如需要)。但这一方法可以让数据加载方式变得十分灵活。
本方法的实践应用可参考文字/字符示例以及Word2Vec电影评论情绪示例对迭代器的应用。
注:在创建自定义的DataSetIterator时,包括输入特征、标签以及任何掩模数组在内的数组都应当按“f”(fortran)顺序创建。有关数组顺序的详情请参阅ND4J用户指南。在实际操作中,这意味着要使用Nd4j.create方法来指定数组顺序:Nd4j.create(new int[]{numExamples, inputSize, timeSeriesLength},'f')。虽然“c”顺序的数组也可以运行,但由于在进行某些运算时需要先将数组复制到“f”顺序,会导致性能有所下降。
示例
DL4J目前提供下列循环网络示例:
- 字符建模示例,可逐个字符地生成莎士比亚风格的散文
- 初级视频帧分类示例,导入视频文件(.mp4格式),对每一帧中的形状进行分类
- word2vec序列分类示例,使用预定型词向量和一个循环神经网络将电影评论分为正面和负面两类。