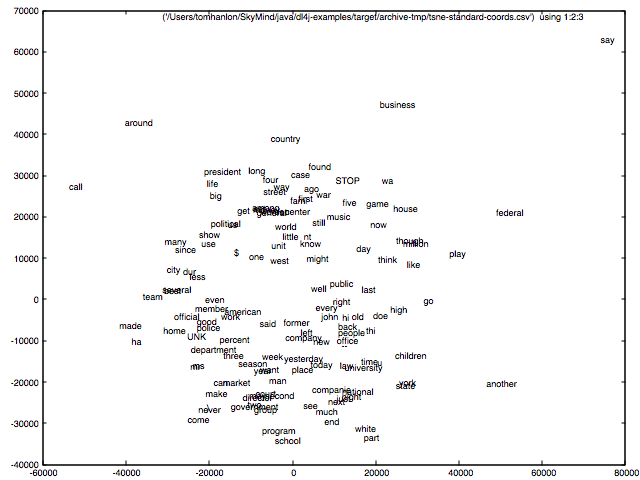
t-SNE的数据可视化
t-分布邻域嵌入算法(t-SNE)是代尔夫特理工大学的Laurens van der Maaten发明的数据可视化工具。
虽然t-SNE(读作“Tee-Snee”)能处理任何数据,但它只在用于已标记数据时才真正有意义,可以明确显示出输入的聚类状况。以下是在DL4J中用t-SNE处理MNIST数据时生成的图像示例。
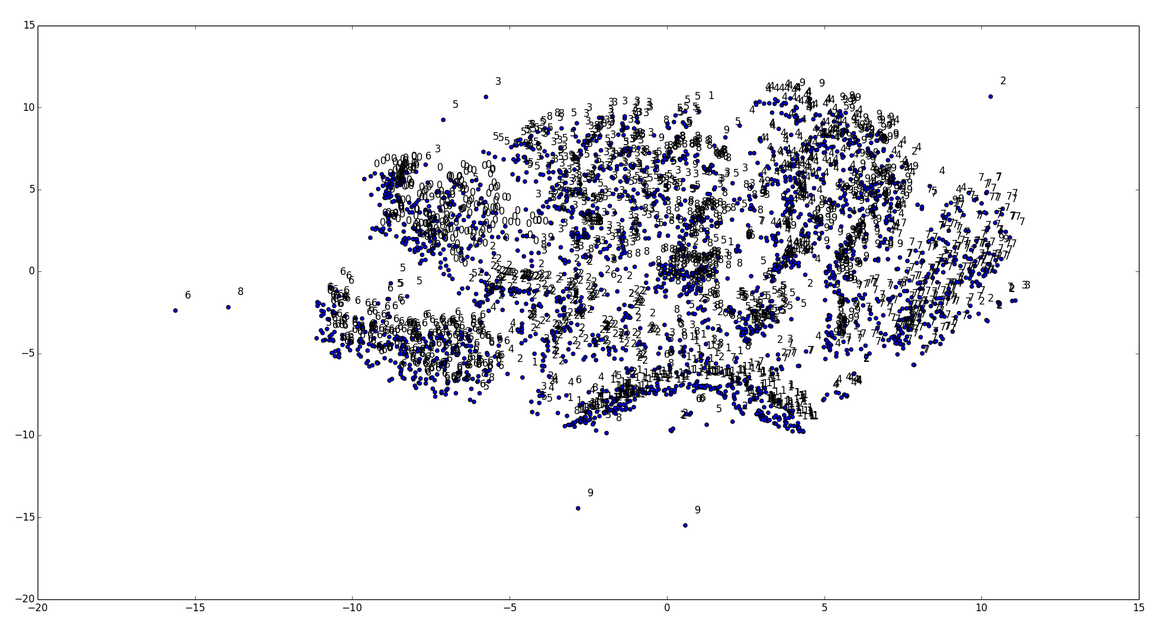
仔细观察上图,您会发现每个数字及其相应的点都聚集在一起。
以下是在Deeplearning4j中使用t-SNE的代码示例。
public class TSNEStandardExample {
private static Logger log = LoggerFactory.getLogger(TSNEStandardExample.class);
public static void main(String[] args) throws Exception {
//第1步:初始化
int iterations = 100;
//创建一个double类型的n维数组
DataTypeUtil.setDTypeForContext(DataBuffer.Type.DOUBLE);
List cacheList = new ArrayList<>(); //cacheList is a dynamic array of strings used to hold all words
//第2步:将文本输入转换为一个词列表
log.info("Load & Vectorize data....");
File wordFile = new ClassPathResource("words.txt").getFile(); //打开文件
//获取所有唯一词向量的数据
Pair<InMemoryLookupTable,VocabCache> vectors = WordVectorSerializer.loadTxt(wordFile);
VocabCache cache = vectors.getSecond();
INDArray weights = vectors.getFirst().getSyn0(); //将每个唯一词的权重分到该词的列表中
for(int i = 0; i < cache.numWords(); i++) //将每个唯一词的字符串分到该词的列表中
cacheList.add(cache.wordAtIndex(i));
//第3步:建立一个双树tsne供之后使用
log.info("Build model....");
BarnesHutTsne tsne = new BarnesHutTsne.Builder()
.setMaxIter(iterations).theta(0.5)
.normalize(false)
.learningRate(500)
.useAdaGrad(false)
// .usePca(false)
.build();
//第4步:确定tsne值并将其保存至文件
log.info("Store TSNE Coordinates for Plotting....");
String outputFile = "target/archive-tmp/tsne-standard-coords.csv";
(new File(outputFile)).getParentFile().mkdirs();
tsne.plot(weights,2,cacheList,outputFile);
//该tsne将把向量的权重作为矩阵,有两个维度,将词字符串作为标签,
//写入前一行创建的outputFile
}
}
以下是一幅用gnuplot所作的tsne-standard-coords.csv文件的图像。