受限玻尔兹曼机解析
受限玻尔兹曼机(RBM)是许多深度学习网络的核心,也是神经网络复兴的关键,因此其工作原理值得进一步深究。
我们将以MNIST为例介绍RBM的工作流程。MNIST数据集包含手写数字零到九的图像,通常用于训练RBM对手写数字图像进行识别和分类,以证明RBM确实能够有效运行。
每个RBM只有两个“节点”层,一个可见层和一个隐藏层。第一个层是接收输入的可见层;这里的输入就是指您提供给神经网络的学习数据。您可以将RBM的输入节点视为存放随机数据样例的容器。每个节点就像一个盒子,储存着一个数据点——在初始层中是像素采样。
在RBM看来,每一幅图像不过是一个需要分类的像素集合。图像分类的唯一依据是特征,亦即像素的鲜明特点。手写数字及其背景由各种边缘、圆弧、夹角、尖端和交叉点组成,而图像的特征正是围绕这些组成部分的较深或较浅色调。
RBM对MNIST数据集进行迭代处理时,一次输入一幅数字图像,但RBM不知道这幅图像是什么。从某种意义上看,RBM其实处于无知的状态,它的唯一目的就是在这种状态下学习辨识图像中的数字;为此,RBM会对未曾出现的数字图像中的像素进行随机采样,测试哪些像素可以帮助它正确识别数字。(学习过程中会有一个包含正确答案的基准测试数据集,或称测试集,训练中的RBM会将自己的初步结论与之进行比对。)
每当预测结果出错时,RBM就会被要求重新尝试,直至发现能够最有效地提示图中数字的像素,亦即能够改善RBM分类能力的信号。造成网络得出错误结论的节点连接会受到惩罚,其重要性被削弱。在弱化这些连接的同时,网络会继续寻找提高准确率、减少误差的路径。
看不见的城市
我们很难想象无法辨识数字是怎样一种感受,所以解释RBM工作原理的一种方法是借助类比。
我们可以把每一幅数字图像想象成一座被迷雾覆盖的城市,它是十座已知城市(旧金山、纽约、新奥尔良、西雅图等)中的一座。RBM会从零开始探索这座城市,逐渐发现一些街道和十字路口。如果碰到一条“华盛顿街”(美国最常见的路名之一),对于RBM辨认城市并无帮助。这就好比是对图像进行采样,获得的像素样本来自于黑色的背景,而不是数字的线条或弯折。背景像素无法提供任何有助于对数据结构进行分类的信息。这些没有特点的像素就相当于华盛顿街。
再以“市场街”为例:纽约、新奥尔良、西雅图和旧金山都有这个名字的街道,但是长度和走向不同。如果采样结果中有许多标记为市场街的样本,那么这座城市更有可能是旧金山或西雅图,因为这两座城市的市场街比纽约和新奥尔良的市场街更长。
与此类似,2、3、5、6、8、9的笔画中都有圆弧,假如一幅未知数字图像的特征包括圆弧,那么图中数字是1、4、7的几率就比较小。所以一段时间之后,RBM会发现圆弧是辨识一部分数字的良好指标,识别圆弧的节点与数字2或3的标签之间的连接路径会被分配更多权重,大于通向1或4的连接。
当然,实际的过程要更复杂一些,因为RBM可以逐层堆叠起来,逐渐综合多组特征。堆叠的RBM称为深度置信网络(DBN),具有重要意义——网络中每增加一个RBM,处理的特征集合就更复杂一些,直至有足够多的RBM组合起来,就能识别整体对象:从像素(输入)开始,到线条、下巴、下颚、下半脸、整个面容,一直到人名(标签)。
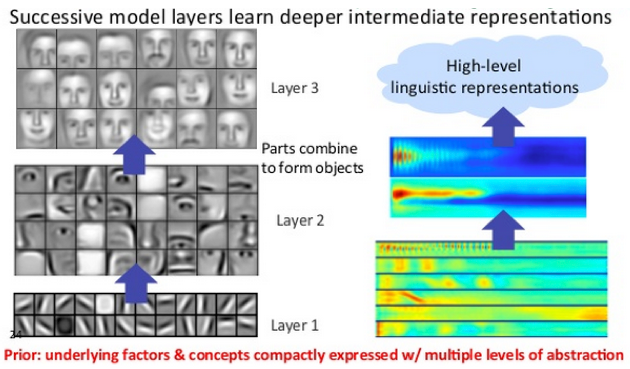
让我们回来看城市的例子,就以两项特征为例。如果一项城市数据样本显示一条市场街与一条名为Van Ness的大道相交,那么这座城市是旧金山的几率很高。同样,如果数字图像的数据样本显示有一竖线与一段向左开口的圆弧相交,那么这幅图中的数字很可能就是5。
现在让我们将数字图像和看不见的城市都想象成地图,图中各个点之间的连接都对应着一定的概率。如果起点是数字8上的一段圆弧(即使我们不知道这是数字8),那么下一个点也是圆弧的概率接近于100%;如果数字是5,那么这一概率就会低一些。
与此相似,假如起点是旧金山的市场街,即便我们不知道自己在旧金山,仍然有很高的几率会在某个时候遇到Van Ness街,因为这两条街都贯穿整个城市,并且在中点相交。
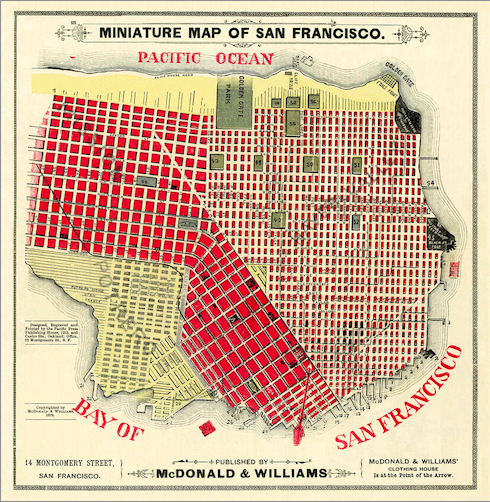
遇到市场街这一简单的特征(表示在深度置信网络一个靠前的隐藏层上)通向另一个更复杂也更少见的特征,即遇到市场街和Van Ness街的交叉点,该特征表示在一个靠后一些的节点层上,由这一节点层将两项特征综合起来。
但我们很可能根本不在旧金山。随着我们进一步深入探索,市场街和Van Ness大道的交叉点不是唯一的节点。
DBN后续层中的隐藏节点还应当考虑到只可能出现在其他城市中的状态(数据状况):例如市场街与FDR路的交叉点表明很有可能是纽约;市场街与Shilshole大道的交叉点表明很有可能是西雅图等。(同样,如果输入节点的初始特征是一段圆弧,那么下一特征可能是圆弧与竖线的交点,表明图中数字是5;或者是另一段圆弧,表明数字是8。)
所以如果最初的市场街数据点是起点,可能有50%的几率遇到Van Ness大道,有10%的几率遇到FDR路,有20%的几率遇到Shilshole大道。但是以更深层的市场街与Van Ness大道交叉点为起点,那么识别结果就有99%的几率是旧金山。纽约和西雅图的情况也与此相似。
同样,虽然许多数字图像(1、4、5、7)多少包含竖线,只有三个数字同时包含横线。而在这三个数字中,有横竖两条线交叉并形成四个90度角的只有4。因此,随着网络深度加大,每个节点的特征组合被逐步扩大,特征组合的出现概率越来越小,与某一特定数字的关联性则不断增大。
马尔可夫链
RBM用一种名为马尔可夫链(Markov Chain)的算法将所有节点联系起来。马尔可夫链本质上是通过概率将两种或更多状态连接起来逻辑回路。就像是一连串的抛硬币、掷骰子,又仿佛罗森克兰茨和吉尔登斯特恩迈向宿命之死。
让我们用另一个超长的类比来解释这一概念。
想像这样一个世界,其中有三个可能的地点,亦即状态,我们姑且称为家、办公室和保龄球馆。这三个状态之间的联系对应着不同的概率,表示从一个点移动至另一个点的可能性。
假设您在家的任意时刻,去保龄球馆的概率较低,为10%,去办公室的概率中等,为40%,而留在原地的可能性较高,为50%。通向各种状态的概率之和应始终等于100%。
我们再看保龄球馆:您在保龄球馆的任意时刻,继续留在那里穿着一步一滑的鞋子喝啤酒的概率较低,因为人们通常打保龄球的时间不会超过几个小时;您去办公室的概率较低,因为通常都是下了班才去打球;而您回家的概率则比较高。假设这三种情况的概率分别为20%、10%和70%。
所以,“在家”这一状态是预示“在办公室”状态的一般指标,是预示“在保龄球馆”状态的较差指标。而“在保龄球馆”这一状态是预示“在家”状态的良好指标,是预示“在办公室”状态的较差指标。(人在办公室的情况就省略了,您可以此类推。)每个状态都像是在小径分叉的花园中一样,但不同路径之间并不平等。
马尔可夫链是序列性的。其目的是让您能比较清楚地知道,对于一种给定的状态,下一状态将会是什么。这些状态不是家、办公室和保龄球馆,而有可能是边缘、交叉点和数字图像,或者街道、社区和城市。马尔可夫链还可以有效预测给定的词集之后最有可能出现哪个词(用于自然语言处理),或者给定的股票价格序列之后股价将如何变化(用于赚很多钱)。
我们用基准数据集来测试RBM的准确率,而RBM会记录引导其得出正确结论的特征。RBM的任务是不断学习并调整特征节点之间连接的概率,最终达到这样的结果:假如RBM收到某个与数字5明确相关的特征,那么节点之间的概率会使RBM得出图中数字为5的结论。RBM能记录哪些特征、特征组与哪个数字图像通常会同时出现。
如果您已做好准备,我们下面就来介绍深度置信网络的实现方法。